-
Benchmarking full scans
With analytics it is common to perform large table scans as all the data needs to be considered. There are flat file options like Parquet but they come with pretty large restrictions. What are the database options like. Here I compare large reads from Mongo, Casandra, and CSV.
I will be running both Mongo and Cassandra from inside Docker.
Mongo
I've used no additional indexes beyond the default
_id. There are 128454284 documents, and the collections stats are:{ "ns" : "bench_test.actions", "count" : 128454284, "size" : 83170724248, "avgObjSize" : 647, "storageSize" : 31919263744, "capped" : false, "wiredTiger" : { "metadata" : { "formatVersion" : 1 }, "creationString" : "allocation_size=4KB,app_metadata=(formatVersion=1),block_allocation=best,block_compressor=snappy,cache_resident=0,checksum=on,colgroups=,collator=,columns=,dictionary=0,encryption=(keyid=,name=),exclusive=0,extractor=,format=btree,huffman_key =,huffman_value=,immutable=0,internal_item_max=0,internal_key_max=0,internal_key_truncate=,internal_page_max=4KB,key_format=q,key_gap=10,leaf_item_max=0,leaf_key_max=0,leaf_page_max=32KB,leaf_value_max=64MB,log=(enabled=),lsm=(auto_throttle=,bloom=,bloom_bit_count=16,bloom_conf ig=,bloom_hash_count=8,bloom_oldest=0,chunk_count_limit=0,chunk_max=5GB,chunk_size=10MB,merge_max=15,merge_min=0),memory_page_max=10m,os_cache_dirty_max=0,os_cache_max=0,prefix_compression=0,prefix_compression_min=4,source=,split_deepen_min_child=0,split_deepen_per_child=0,spli t_pct=90,type=file,value_format=u", "type" : "file", "uri" : "statistics:table:collection-4--6983004796286940855", "LSM" : { "bloom filters in the LSM tree" : 0, "bloom filter false positives" : 0, "bloom filter hits" : 0, "bloom filter misses" : 0, "bloom filter pages evicted from cache" : 0, "bloom filter pages read into cache" : 0, "total size of bloom filters" : 0, "sleep for LSM checkpoint throttle" : 0, "chunks in the LSM tree" : 0, "highest merge generation in the LSM tree" : 0, "queries that could have benefited from a Bloom filter that did not exist" : 0, "sleep for LSM merge throttle" : 0 }, "block-manager" : { "file allocation unit size" : 4096, "blocks allocated" : 2644015, "checkpoint size" : 31917375488, "allocations requiring file extension" : 2640313, "blocks freed" : 9264, "file magic number" : 120897, "file major version number" : 1, "minor version number" : 0, "file bytes available for reuse" : 2068480, "file size in bytes" : 31919263744 }, "btree" : { "btree checkpoint generation" : 74, "column-store variable-size deleted values" : 0, "column-store fixed-size leaf pages" : 0, "column-store internal pages" : 0, "column-store variable-size RLE encoded values" : 0, "column-store variable-size leaf pages" : 0, "pages rewritten by compaction" : 0, "number of key/value pairs" : 0, "fixed-record size" : 0, "maximum tree depth" : 5, "maximum internal page key size" : 368, "maximum internal page size" : 4096, "maximum leaf page key size" : 3276, "maximum leaf page size" : 32768, "maximum leaf page value size" : 67108864, "overflow pages" : 0, "row-store internal pages" : 0, "row-store leaf pages" : 0 }, "cache" : { [4/1859] "bytes read into cache" : 84523119969, "bytes written from cache" : 84498646329, "checkpoint blocked page eviction" : 0, "unmodified pages evicted" : 2433644, "page split during eviction deepened the tree" : 2, "modified pages evicted" : 14260, "data source pages selected for eviction unable to be evicted" : 995, "hazard pointer blocked page eviction" : 480, "internal pages evicted" : 6424, "internal pages split during eviction" : 58, "leaf pages split during eviction" : 11688, "in-memory page splits" : 10943, "in-memory page passed criteria to be split" : 24955, "overflow values cached in memory" : 0, "pages read into cache" : 2631923, "pages read into cache requiring lookaside entries" : 0, "overflow pages read into cache" : 0, "pages written from cache" : 2643920, "page written requiring lookaside records" : 0, "pages written requiring in-memory restoration" : 0 }, "compression" : { "raw compression call failed, no additional data available" : 0, "raw compression call failed, additional data available" : 0, "raw compression call succeeded" : 0, "compressed pages read" : 2620214, "compressed pages written" : 2618049, "page written failed to compress" : 1, "page written was too small to compress" : 25870 }, "cursor" : { "create calls" : 6, "insert calls" : 128454284, "bulk-loaded cursor-insert calls" : 0, "cursor-insert key and value bytes inserted" : 83796127832, "next calls" : 129280601, "prev calls" : 1, "remove calls" : 0, "cursor-remove key bytes removed" : 0, "reset calls" : 129494236, "restarted searches" : 17285696, "search calls" : 0, "search near calls" : 1020074, "truncate calls" : 0, "update calls" : 0, "cursor-update value bytes updated" : 0 }, "reconciliation" : { "dictionary matches" : 0, "internal page multi-block writes" : 1576, "leaf page multi-block writes" : 10976, "maximum blocks required for a page" : 16, "internal-page overflow keys" : 0, "leaf-page overflow keys" : 0, "overflow values written" : 0, "pages deleted" : 28, "fast-path pages deleted" : 0, "page checksum matches" : 11655, "page reconciliation calls" : 17577, "page reconciliation calls for eviction" : 2569, "leaf page key bytes discarded using prefix compression" : 0, "internal page key bytes discarded using suffix compression" : 2621632 }, "session" : { "object compaction" : 0, "open cursor count" : 6 }, "transaction" : { "update conflicts" : 0 } }, "cache" : { [4/1859] "bytes read into cache" : 84523119969, "bytes written from cache" : 84498646329, "checkpoint blocked page eviction" : 0, "unmodified pages evicted" : 2433644, "page split during eviction deepened the tree" : 2, "modified pages evicted" : 14260, "data source pages selected for eviction unable to be evicted" : 995, "hazard pointer blocked page eviction" : 480, "internal pages evicted" : 6424, "internal pages split during eviction" : 58, "leaf pages split during eviction" : 11688, "in-memory page splits" : 10943, "in-memory page passed criteria to be split" : 24955, "overflow values cached in memory" : 0, "pages read into cache" : 2631923, "pages read into cache requiring lookaside entries" : 0, "overflow pages read into cache" : 0, "pages written from cache" : 2643920, "page written requiring lookaside records" : 0, "pages written requiring in-memory restoration" : 0 }, "compression" : { "raw compression call failed, no additional data available" : 0, "raw compression call failed, additional data available" : 0, "raw compression call succeeded" : 0, "compressed pages read" : 2620214, "compressed pages written" : 2618049, "page written failed to compress" : 1, "page written was too small to compress" : 25870 }, "cursor" : { "create calls" : 6, "insert calls" : 128454284, "bulk-loaded cursor-insert calls" : 0, "cursor-insert key and value bytes inserted" : 83796127832, "next calls" : 129280601, "prev calls" : 1, "remove calls" : 0, "cursor-remove key bytes removed" : 0, "reset calls" : 129494236, "restarted searches" : 17285696, "search calls" : 0, "search near calls" : 1020074, "truncate calls" : 0, "update calls" : 0, "cursor-update value bytes updated" : 0 }, "reconciliation" : { "dictionary matches" : 0, "internal page multi-block writes" : 1576, "leaf page multi-block writes" : 10976, "maximum blocks required for a page" : 16, "internal-page overflow keys" : 0, "leaf-page overflow keys" : 0, "overflow values written" : 0, "pages deleted" : 28, "fast-path pages deleted" : 0, "page checksum matches" : 11655, "page reconciliation calls" : 17577, "page reconciliation calls for eviction" : 2569, "leaf page key bytes discarded using prefix compression" : 0, "internal page key bytes discarded using suffix compression" : 2621632 }, "session" : { "object compaction" : 0, "open cursor count" : 6 }, "transaction" : { "update conflicts" : 0 } }, "cache" : { [4/1859] "bytes read into cache" : 84523119969, "bytes written from cache" : 84498646329, "checkpoint blocked page eviction" : 0, "unmodified pages evicted" : 2433644, "page split during eviction deepened the tree" : 2, "modified pages evicted" : 14260, "data source pages selected for eviction unable to be evicted" : 995, "hazard pointer blocked page eviction" : 480, "internal pages evicted" : 6424, "internal pages split during eviction" : 58, "leaf pages split during eviction" : 11688, "in-memory page splits" : 10943, "in-memory page passed criteria to be split" : 24955, "overflow values cached in memory" : 0, "pages read into cache" : 2631923, "pages read into cache requiring lookaside entries" : 0, "overflow pages read into cache" : 0, "pages written from cache" : 2643920, "page written requiring lookaside records" : 0, "pages written requiring in-memory restoration" : 0 }, "compression" : { "raw compression call failed, no additional data available" : 0, "raw compression call failed, additional data available" : 0, "raw compression call succeeded" : 0, "compressed pages read" : 2620214, "compressed pages written" : 2618049, "page written failed to compress" : 1, "page written was too small to compress" : 25870 }, "cursor" : { "create calls" : 6, "insert calls" : 128454284, "bulk-loaded cursor-insert calls" : 0, "cursor-insert key and value bytes inserted" : 83796127832, "next calls" : 129280601, "prev calls" : 1, "remove calls" : 0, "cursor-remove key bytes removed" : 0, "reset calls" : 129494236, "restarted searches" : 17285696, "search calls" : 0, "search near calls" : 1020074, "truncate calls" : 0, "update calls" : 0, "cursor-update value bytes updated" : 0 }, "reconciliation" : { "dictionary matches" : 0, "internal page multi-block writes" : 1576, "leaf page multi-block writes" : 10976, "maximum blocks required for a page" : 16, "internal-page overflow keys" : 0, "leaf-page overflow keys" : 0, "overflow values written" : 0, "pages deleted" : 28, "fast-path pages deleted" : 0, "page checksum matches" : 11655, "page reconciliation calls" : 17577, "page reconciliation calls for eviction" : 2569, "leaf page key bytes discarded using prefix compression" : 0, "internal page key bytes discarded using suffix compression" : 2621632 }, "session" : { "object compaction" : 0, "open cursor count" : 6 }, "transaction" : { "update conflicts" : 0 } }, "cache" : { [4/1859] "bytes read into cache" : 84523119969, "bytes written from cache" : 84498646329, "checkpoint blocked page eviction" : 0, "unmodified pages evicted" : 2433644, "page split during eviction deepened the tree" : 2, "modified pages evicted" : 14260, "data source pages selected for eviction unable to be evicted" : 995, "hazard pointer blocked page eviction" : 480, "internal pages evicted" : 6424, "internal pages split during eviction" : 58, "leaf pages split during eviction" : 11688, "in-memory page splits" : 10943, "in-memory page passed criteria to be split" : 24955, "overflow values cached in memory" : 0, "pages read into cache" : 2631923, "pages read into cache requiring lookaside entries" : 0, "overflow pages read into cache" : 0, "pages written from cache" : 2643920, "page written requiring lookaside records" : 0, "pages written requiring in-memory restoration" : 0 }, "compression" : { "raw compression call failed, no additional data available" : 0, "raw compression call failed, additional data available" : 0, "raw compression call succeeded" : 0, "compressed pages read" : 2620214, "compressed pages written" : 2618049, "page written failed to compress" : 1, "page written was too small to compress" : 25870 }, "cursor" : { "create calls" : 6, "insert calls" : 128454284, "bulk-loaded cursor-insert calls" : 0, "cursor-insert key and value bytes inserted" : 83796127832, "next calls" : 129280601, "prev calls" : 1, "remove calls" : 0, "cursor-remove key bytes removed" : 0, "reset calls" : 129494236, "restarted searches" : 17285696, "search calls" : 0, "search near calls" : 1020074, "truncate calls" : 0, "update calls" : 0, "cursor-update value bytes updated" : 0 }, "reconciliation" : { "dictionary matches" : 0, "internal page multi-block writes" : 1576, "leaf page multi-block writes" : 10976, "maximum blocks required for a page" : 16, "internal-page overflow keys" : 0, "leaf-page overflow keys" : 0, "overflow values written" : 0, "pages deleted" : 28, "fast-path pages deleted" : 0, "page checksum matches" : 11655, "page reconciliation calls" : 17577, "page reconciliation calls for eviction" : 2569, "leaf page key bytes discarded using prefix compression" : 0, "internal page key bytes discarded using suffix compression" : 2621632 }, "session" : { "object compaction" : 0, "open cursor count" : 6 }, "transaction" : { "update conflicts" : 0 } }, "nindexes" : 1, "totalIndexSize" : 1303175168, "indexSizes" : { "_id_" : 1303175168 }, "ok" : 1 }Basic Read
Here is the script I used, very basic:
from pymongo import MongoClient actions = MongoClient()['bench_test']['actions'].find() count = 0 print("Starting") for i in actions: if count % 100000 == 0: print(count) count += 1 print("Done")Execution #1
real 35m37.049s user 25m22.424s sys 1m44.028sExecution #2
real 27m43.629s user 18m40.636s sys 1m33.896sI did notice that python process was taking about 80% CPU which gives me some worry about Python being the bottleneck. Mongo around 20%. DiskIO is pretty fine at 10% and disk read throughput at 13.3M/s.
Projection
But I know there is a lot of extra information in the documents. What if I wanted to isolate just 'customer-id' and 'timestamp'
Projection - script
from pymongo import MongoClient p = {'timestamp': 1, 'customer-id': 1, '_id': 0} actions = MongoClient()['bench_test']['actions'].find({}, p) count = 0 print("Starting") for i in actions: if count % 100000 == 0: print(count) count += 1 print("Done")Projection - Run #1
real 11m0.640s user 3m17.836s sys 0m25.832s
Projection - Run #2
real 10m57.515s user 3m16.616s sys 0m25.736s
Timestamp restriction
I added an index on
{'timestamp': 1}. This yielded 91,080,438 documents.Timestamp restriction - script:
from datetime import datetime from pymongo import MongoClient q = {'timestamp': {'$gte': datetime(2015, 01, 01), '$lt': datetime(2016, 01, 01)} } actions = MongoClient()['bench_test']['actions'].find(q) count = 0 print("Starting") for i in actions: if count % 100000 == 0: print(count) count += 1 print("Total") print(count) print("Done")Timestamp resctriction - Run #1
real 23m43.569s user 13m39.052s sys 0m49.560sTimestamp resctriction - Run #2
Total Done real 23m54.677s user 13m34.628s sys 0m57.328sCopy time
real 38m19.203s user 18m26.760s sys 0m49.268sWhat if, I didn't just supply a projection, but only stored the data I was interested in. I re-wrote out the collection so that I was only storing 'customer-id' and 'timestamp'.
Run #1 real 8m39.873s user 5m27.732s sys 1m0.084s
Run #2 real 7m42.522s user 5m39.204s sys 1m12.464s
Same data set now with index on
{'timestamp': 1}and time restriction:Run #1 real 9m7.167s user 6m19.084s sys 0m35.272s
Run #2 real 6m3.538s user 4m12.300s sys 0m25.560s
-
Jupyter Spark (Scala) Notebooks from start to end.
Performed on fresh Ubuntu 14.04 install.
First, make sure you have Java and SBT installed.
http://www.webupd8.org/2012/09/install-oracle-java-8-in-ubuntu-via-ppa.html
http://www.scala-sbt.org/download.html
git clone https://github.com/ibm-et/spark-kernel.git cd spark-kernelTechnically I have used my own fork/branch because at the moment there is a bug in the make file see here for diff.
make build make distSomewhere in all the output from those commands you will see something similar to:
APACHE_SPARK_VERSION=1.5.1Go to http://spark.apache.org/downloads.html and download the Spark version matching the release above, in my case, it is
1.5.1, be sure to also selectPre-built for Hadoop 2.6 and later.Extract:
tar xvzf spark-1.5.1-bin-hadoop2.6.tgzPersonally I like to have a Spark server that runs continuously with standalone mode as it is better for viewing historical jobs through the web interface, so, start it up:
sudo spark-1.5.1-bin-hadoop2.6/sbin/start-all.shI got
[sudo] password for tory: starting org.apache.spark.deploy.master.Master, logging to /home/tory/spark-1.5.1-bin-hadoop2.6/sbin/../logs/spark-root-org.apache.spark.deploy.master.Master-1-tory-VirtualBox.out localhost: ssh: connect to host localhost port 22: Connection refusedWoops, I forgot that the root user needs to be able to SSH into localhost without a password. So lets set that up. First, become root, there is lots of root stuff:
(In hindisght, I wonder if I could do this without root, maybe.)
sudo suIs the sshd service running?
# service ssh status ssh: unrecognized serviceNegative, lets install
# apt-get install openss-serverConfig that stuff. First, allow logging in with root:
# sed -e "s/PermitRootLogin/PermitRootLogin\ yes/" /etc/ssh/sshd_config > /etc/ssh/sshd_config.tmp # cp /etc/ssh/sshd_config.tmp /etc/ssh/sshd_configDisable password login since we just did something dangerous:
# sed -e "s/.*PasswordAuthentication.*/PasswordAuthentication no/" /etc/ssh/sshd_config > /etc/ssh/sshd_config.tmp # cp /etc/ssh/sshd_config.tmp /etc/ssh/sshd_configJust to be double sure, I will do what I think only allows root from localhost to SSH into the box, I'm not 100% sure about this, but here it is:
# echo "AllowUsers root@localhost" >> /etc/ssh/sshd_configRestart sshd and check status:
# service ssh restart ssh stop/waiting ssh start/running, process 6109 # service ssh status ssh start/running, process 6109Make keys (press enter until it stops asking you questions):
# ssh-keygenMake the new key authorized:
# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keysTest the connection (type yes):
# ssh root@localhost "echo hi" The authenticity of host 'localhost (127.0.0.1)' can't be established. ECDSA key fingerprint is ..... Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts. hiIf it says 'hi' you are good. Back to spark.
Try and start the Spark server again:
# ./spark-1.5.1-bin-hadoop2.6/sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /home/tory/spark-1.5.1-bin-hadoop2.6/sbin/../logs/spark-root-org.apache.spark.deploy.master.Master-1-tory-VirtualBox.out localhost: starting org.apache.spark.deploy.worker.Worker, logging to /home/tory/spark-1.5.1-bin-hadoop2.6/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-tory-VirtualBox.outGo to
http://localhost:8080/and you should see something like:
URL: spark://tory-VirtualBox:7077 REST URL: spark://tory-VirtualBox:6066 (cluster mode) Alive Workers: 1 Cores in use: 4 Total, 0 Used Memory in use: 6.8 GB Total, 0.0 B Used Applications: 0 Running, 0 Completed Drivers: 0 Running, 0 Completed Status: ALIVEDo make sure there is an alive worker.
Install Jupyter:
# pip3 install jupyter The program 'pip3' is currently not installed. You can install it by typing: # apt-get install python3-pipWoops try this again:
# apt-get install -y python3-pip && pip3 install jupyterBack to non-root user, install Spark kernel we built earlier:
(I Ran this, don't think it was needd, but in case it was, here it is.)
jupyter kernelspec install --user /home/tory/spark-kernel/etc/bin/ [InstallKernelSpec] Installed kernelspec in /home/tory/.local/share/jupyter/kernels/Set your Jupyter Dir:
export JUPYTER_DATA_DIR=~/.jupyterCreate folder
mkdir -p $JUPYTER_DATA_DIR/kernels/sparkOpen/create file at
$JUPYTER_DATA_DIR/kernels/spark/kernel.jsonwith contents:{ "display_name": "Spark 1.5.1", "language": "scala", "argv": [ "/home/tory/spark-kernel/dist/spark-kernel/bin/spark-kernel", "--profile", "{connection_file}" ], "codemirror_mode": "scala", "env": { "SPARK_OPTS": "--master=spark://tory-VirtualBox:7077" } }Careful to modify the kernel path to your environment, same with the
SPARK_OPTSyou can get this address from the earlier webpage at http://localhost:8080/Then start your Jupiter notebook:
jupyter notebookClick 'new' on the right and then choose Spark!
Oh no!
Dead Kernel The kernel has died, and the automatic restart has failed. It is possible the kernel cannot be restarted. If you are not able to restart the kernel, you will still be able to save the notebook, but running code will no longer work until the notebook is reopened.Lets look at the terminal
SPARK_HOME must be set to the location of a Spark distribution!Riiiiighhhhht, lets fix that:
export SPARK_HOME=/home/tory/spark-1.5.1-bin-hadoop2.6/Start Jupyter again and click new. Should be working now. Test it out by taking a code sample roughtly from http://spark.apache.org/examples.html. Paste the following into a notebook:
val NUM_SAMPLES = 1000 val count = sc.parallelize(1 to NUM_SAMPLES).map{i => val x = Math.random() val y = Math.random() if (x*x + y*y < 1) 1 else 0 }.reduce(_ + _) println("Pi is roughly " + 4.0 * count / NUM_SAMPLES)Press ctrl+enter to run it and you should get your answer
Pi is roughly 3.152.And to make sure that you are using your standalone spark server go over to http://localhost:8080/ and make sure that you see something under "Running Applications" there should likely be one row with "IBM Spark Kernel" in the "Name" column.
Alright, you are done, kinda, it works, that is true. Some of the paths aren't elegant. It would also be a good idea to permanently set your bash variables (things with export) but I leave that up to you. Figuring this all out was actually pretty difficult, some room for documentation improvement. Also, at one point I downloaded Spark 1.5.2 when I should have 1.5.1 but I think I backtracked properly, though, I think 1.5.2 actually works.
-
Using Eclipe with Python Behave
Two things I want to accomplish. Get rid of PyDev errors and use the Eclipse "run" functionality.
Get rid of "unused wild import"
from behave import when, theninstead offrom behave import *insteps.pyGet rid of
Unresolved Import: whenandUnresolved Import: thenby adding "Behave" as a "Forced Builtin." To do this,Window>Preferences>PyDev>Interperters>Python Interperter>Forced Builtins>NewMake sure that during that process your Python interpreter is setup correctly including the your libraries path. I had to close steps.py and re-open it before the errors went away.Get rid of
Duplicated signature: step_impl, for this I will just turn off error checking for duplicate signatures since this isn't really an error I make very often. To turn it off,Window>Preferences>PyDev>Editor>Code Analysis>Others>Duplicated Signature>IgnoreSetup the built in run. "Run>Run Configurations>Python Run" Create a new run. In Main>Project set your project. For the Main Module choose your version of "/home/tory/Desktop/demo/virtual_env/bin/behave" Inside the Arguments tab set the Working Direcotry, this is where your something.feature file exists. And now you should be set. Typically when you run "behave" outiside of the IDE you just type "Behave". This simply launches a Python executable with a shebang at the top. From the IDE (Eclipse) we are simply are calling the Behave executable using a python executable instead of relying on the shebang. We also have to specify the current working directory.
-
Creating a Python3 virtual environment
virtualenv -p /usr/bin/python3 virtual_envWhere virtual_env is arbitrary.
Also may be required,
sudo apt-get install python-pip sudo pip install virtualenv -
Move files in directory containing a string.
Move all files containing the text "status: draft" to another folder.
for i in `grep -l "status: draft" *`; do mv $i ~/Documents/jekyllDrafts/; done; -
Extract text with sed
Here I search for the contents of all src (from an HTML tag) attributes in the files in a folder.
sed -n 's/.*src="\([^"]*\).*/\1/p' * -
Change/rename extension for every file in a folder
Here I go from .html to .markdownfor i in `ls *.html`; do file_name=`echo $i | sed 's/\.[^.]*$//'`; \ mv $file_name.html $file_name.markdown; done; -
Your encoding may be okay, you may just not know it.
I recently realized that dumping a Python dictionary to the terminal may give different results compared to printing a particular value to the screen. It's best to demonstrate by example using the Python repl.
>>> dict = {"str": "à"} >>> print(dict) {'str': '\xc3\xa0'} >>> print(dict['str']) à >>> repr(dict['str']) "'\\xc3\\xa0'"As you can see dumping the dictionary to the terminal does not display the special characters. Because of this I spent far too long (40 minutes?) trying to figure out why the source of my text was faulty, when in fact it was simply the way I was displaying the text that was faulty.
Lets try the same code using python 3.4
>>> dict = {"str": "à"} >>> print(dict) {'str': 'à'} >>> repr(dict['str']) "'à'"As we can see here Python 3.4 has no problem handling these characters.
-
Reading news through text messages
Mobile text messages, logically, really just send data, just like what mobile providers call data, although at a slow rate. My mobile service plan has unlimited text messages but limited data. I was thinking I could use the text message data in place of "data data" for certain things.
I have set up a system, demonstrated on the right, that will let me read the news via text message, no mobile data required. As you will see, it is quite slow, but, this was never intended to be used in a serious manner anyway. The "M" requests the main menu, a number requests a menu item, "N" requests more of the content since only so much content can fit in a single message and I did not want to send an unstoppable flood of messages, and a "$" at the end of the message signifies that there is nothing left to send, that is, you can not send "N" to get more content.
To give a high-level overview, I will start
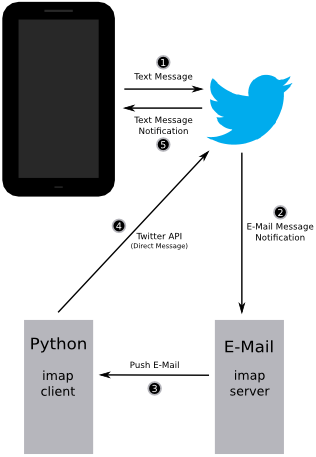 by briefly describing one communication cycle of the system. It is the most interesting part and the rest of the information in this post is just extra rambling for those really interested.
by briefly describing one communication cycle of the system. It is the most interesting part and the rest of the information in this post is just extra rambling for those really interested.Logical flow of one communication cycle:
- The user first sends a command to Twitter via text message. Commands are sent as one Twitter user and received by another. The same user that received the command will later be the one who sends the content back to the mobile phone. The user who sent the command will receive the content. Another way to put it, there is a Twitter account for the phone and another not for the phone.
- Twitter will send out an e-mail notification in response to this command.
- The e-mail server will send a push alert of the e-mail it received from Twitter and the Python IMAP client will receive this email and go out to the internet and gather content if required.
- The Python e-mail client then sends the content to Twitter via the Twitter API and a Twitter direct message.
- Twitter receives the direct message and sends out a text message notification.
The system is made up of two main components.
One, a custom Android application which sends and receives SMS messages. Originally this aspect was not thought to be required. I planned to send SMS messages through the email to text message and text message to email services that my mobile service provides. But I found that my service provider seems to rate limit these messages since messages would stop being delivered after sending a handful of them. It seems I could send unlimited messages from text message to e-mail but the rate limit kicked in on the way back (e-mail to text message). I could maybe send 20 before they stopped being delivered. I phoned and messaged my service provider about the situation, they did not know what the problem was and in some cases they did not even know the functionality existed.
Since using the text message to e-mail and e-mail to text message services was ruled out I decided to use use Twitter since it offers text message notifications for things like direct messages. I considered a few other services. I looked at Google, they seem to offer some sort of SMS service but it turns out it is not available for Canada. On a side note, I wonder why this is, I consider Canada to be more technologically advanced than some of the listed countries. I considered Facebook, but Facebook did not seem to reliably deliver text messages. I looked at a few free services but they seemed sketchy. I also looked at Skype.
Twitter is quite reliable but it comes with a few downsides. It adds a bunch of text of its own to every message, letting you know that it is a message from Twitter, who it is from and how to reply to it. As a result, a tweet taking up the entire 140 characters spans across two text messages. This creates two problems. One, it often results in messages arriving out of order, and two, the second message seems to take a longer period of time to arrive, as if again, my service provider is rate limiting me when two text messages are sent to me in a fast fashion. I considered only sending smaller messages so that Twitter could always deliver the message in one text message but I figured this would be slower since relatively more messages would be required since there is less Twitter boilerplate when the message spans two text messages when compared to sending two Twitter messages. This is because Twitter only tells you who the message is from for one Twitter message (even if it spans two text messages), thus a second text message (from the single Twitter message) would not include this boilerplate. If I sent two Twitter messages I'd get two text messages with two sets of boiler plate. Receiving boiler plate, and even messages out of order was not that big of a problem compared to the problems with sending a reply since my eyes can easily filter the boilerplate out, but replies required typing boilerplate. In order to reply to a Twitter direct message via text message you have to write "DM @twitterHandle theMessage." This means that where I send the message "M" to get the main menu I would have had to type "DM @twitterHandle M" which would not be very usable at all. I looked into perhaps finding an SMS Android application with canned responses, macros or snippets, but my searching was not yielding fruitful results.
Thus, I decided to write my first small Android application. This application would parse incoming messages removing the Twitter boilerplate and make sure that messages were ordered properly. This meant that if the second message arrived first the application would wait until the first message arrived before displaying either. For consistency, if the message is multi-part it also waits for the whole message if the first message arrives first. The application also extracts the actual content of the message and displays the message hiding the rest of the information. The application also makes replying easier by automatically inserting the "DM @twitterHandle" aspect.
Two, a custom IMAP client. This is the first component of the system that I wrote. It uses the IDLE functionality to listen to a local self-hosted e-mail server running Dovecot in a virtual machine in order to receive push notifications when e-mail arrives. Once I made the move to Twitter I thought that this could be replaced with the Twitter API but it did not seem like receiving push notifications from Twitter was possible or easy at this point. There is evidence that they are going to make this possible in the future because it seems as if there is a private beta, but for the time being this did not seem like a plausible route. This is okay because the push e-mail notifications work really well anyway. Twitter delivers the email quickly and my IMAP client gets the notifications from the e-mail server nearly instantaneous.
The e-mail client receives notifications from Twitter and parses the e-mail to extract the message, extracting commands like "M" for main menu. It then gathers the content which it needs to send, it makes a few other notes for later, such as when a user enters "N" and requests more of the content and more messages. It then replies to Twitter via a direct message and the Twitter API. The e-mail client has to handle the fact that content which it wishes to send will often be longer than the Twitter maximum of 150 characters.
The gathering content aspect is rather quite neat. In the video I demonstrated it working with CBC Toronto but it is actually very flexible. Getting the CBC Toronto links was hard-coded to a degree but the gathering of the article would be nearly universal to any reasonably coded web page. This means that in the future, though unlikely to be honest (since this was just an experiment), I could add Reddit capability. Reddit would otherwise pose a problem since what it links to is not well defined at all. The way the article content is extracted is by analysing the structure of the web page and guessing which section is the main content. It does this by looking for the div or article tag which contains the most text and the least amount of other tags. This works because the actual content portion of a web page usually has relatively long sections of text without much HTML mark-up. There are a few other conditions to this but that is mostly how it works. Some tags are ignored such as the paragraph tag or the list item tag. This is because the paragraph tag is almost exclusively used for main content and a long list could have many list tags which would raise the tag count significantly. There were also problems like the situation where a div contains one word because that div tag would be 100% comprised of text and thus be very favourable in the text to tag ratio. This happened in situations like
Widgets Inc.. These problems were dealt with and I was able to successfully test on several web pages chosen at random.This system because of its speed, and perhaps its complexity makes it not very practical. Aside from the intelligent content extractor, there is one potentially useful part of this experiment, it is making an Android SMS client that facilitates communication with Twitter like I have but takes it further. I could fairly easily group the SMS messages that are received from Twitter by Twitter user and allow the Android user to respond to whoever sent the message (rather than a fixed user as is the case with my application (very simple modification)). This would enable someone to chat on Twitter with their mobile despite not having a data connection. It would behave like a normal SMS application but using Twitter.
It was a fun experiment and proof of concept. I learned a lot, particularly about Android development since I had never done it before. I also figure that Twitter does not like me doing this much so I am unlikely to use this system much if at all. The primary reason I use mobile data is when I am waiting for something, like when at the dentist and waiting for my appointment. This system could be useful if I decided to reduce my data plan because I could occupy the time without using data and instead use text messages. The delay in the system would not be much of a bother since there would be no expectation or real care if it were fast or not. Though perhaps reading a pre-downloaded book would be more useful. Out of curiosity it would be amusing to transmit a small image via text messages.
-
Create .accdb/.xlsx (Access/Excel) or SQL Server Connection for Crystal Reports
For Access/Excel, when creating a new connection for a Microsoft Access/Excel 2007 (+?) database you need to select "OLE DB (ADO)" as opposed to "Access/Excel (DAO)" which is for 2003 or perhaps earlier. After, you choose "Microsoft Office 12.0 Access Database Engine OLE DB Provider". I found this non-intuitive so I'm making note of it here. After selecting that, you will now have a menu where you can choose "Office Database Type" where you can select "Access" or "Excel". On this same menu, in the "Data Source" field you locate the actual data file. The rest is fairly intuitive.
For SQL Server, the steps are pretty similar, you select "OLE DB (ADO)" and then "Microsoft OLE DB Provider for SQL Server". You then need to fill out the connection information. After filling in the Server, User ID and the Password you will be able to select a database. The login credentials can be skipped if you choose Integrated Security which uses your Windows credentials.
-
Arch Linux Crontab Not Running
My cron was not running, it appears that the cron service is not enabled by default on a new Arch Linux install. I enabled it with:
systemctl start cronie systemctl start cronie.service -
Really easy é typing in Ubuntu
I do have my compose key setup so that typing an é can be a matter of pressing
+ e + ' but é seems to come up enough with French that having an even easier way to type it would be handy. So, I did what I have shown below. Now I can type an é by pressing + e + e (one after another). It is the same amount of keystrokes, but considerably easier. After adding the following content to the following files I needed to log out and back in again. ~/.XCompose include "%L" # import the default Compose file for your locale <Multi_key> <e> <e> : "é"~/.profile
export GTK_IM_MODULE="xim" -
The Aquariums of Pyongyang - Ten Years in the North Korean Gulag [book notes]
By: Kang Chol-Hwan and Pierre Rigoulot Translated by: Yair Reiner This was a really interesting book, I enjoyed it very much (not in the way one enjoys a trip to an amusement park, obviously). It of course revealed that the conditions in North Korea are terrible. It gave an account of the situation that was described as relatively good despite still being terrible. I often assume that I know what terrible is, but regularly as I search through media from terrible places and situations, my understanding of terrible is surpassed. It has got to be hard for me to imagine, like fathoming a 4th dimension or what it's like to have the senses of a bat, the experience is simply not available for me to understand, but the account offered in this book does bring me closer to understanding. The account of the prison camps was particularly interesting because of the author's young age and innocence. It's amazing to think that at certain points he thought that what was happening was normal. As the author himself sometimes describes, it is like hearing about “another universe” where hot freezes and cold burns. When I mention the author, I mean Kang Chol-Hwan PREFACE
- it wasn't until after ww2 that the atrocities committed by the Nazis in relation to the Jewish people came till light. Could this happen with North Korea?
- history of how North Korea came to exist
- female human trafficking into China
- stunted growth of children
- in the 1960s the North and South were on par with regards to economic development
- Renounced but often used in private, regarding the age of a person, year one starts when conceived, and incremented on each January first http://en.wikipedia.org/wiki/EastAsianagereckoning though according to <a href="http://www.reddit.com/r/todayilearned/comments/14jesr/tilthatineastasiancountrieslikekoreayou/c7dpedi">http://www.reddit.com/r/todayilearned/comments/14jesr/tilthatineastasiancountrieslikekorea_you/c7dpedi this does not have to do with time spent in the womb
- In school there were “self-criticism” sessions, where children would denounce themselves for not living up to the standards of the Great Leader. Apparently they weren't as bad as they sound, that they were supposed to serve as encouragement to do better.
- Pupil's Red Army
- fake guns
- marching
- fun
- author seems to have had a fun childhood
- seemed exceptionally well off in comparison to others though
- other places, and big cities seemed to be doing okay
- “According to Confucian tradition, which continues to hold sway in present-day Korea, a married woman belongs to her husband's family and remains so, irrespective of divorce or separation. If she tries to return to her parents' home, she will most likely be turned away.”
- describes how the author ended up wealthy (grandfather was rich from enterprises in Japan)
- Discussed family's move from Japan to North Korea, quickly realized it was a horrible decision
- grandfather taken by security forces one day at work, security forces lied to family about whereabouts, eventually came to take the family
- security forces searched the house, stole plenty of their belongings for themselves, gave others to the government
- interesting, much of this is told from the author's perspective who was at the time, 9 years old, which makes the story quite interesting because of his innocence, he wasn't even aware of what was going on, initially he thought that it might even be fun going off into the country, but he was concerned about his pet fish.
- there exists “school” in the camps for prisoner children that ran half the day, the other half would be labour
- guard families and guards were well off, lived separate from the prisoners
- described the family's introduction to the camp
- devices used to prevent escape, including animal traps, depended on mountains etc for natural barriers
- ways teachers would address students:
- "Hey, you, in the back of the room!”
- “Hey, you, the idiot in the third row!”
- “Hey, you, son of a whore.”
- One of the teachers described as “an adept technician of suffering, always searching for a way to maximize pain.”
- some punishment came in the form of digging ditches, filling them in, then digging more ditches and filling them in
- described school and some of the child labour
- Described an interesting situation regarding the effects of not distinguishing individuals of a team from the team, judging the output of the team and punishing the entire team if the output didn't meet standards. This had the effect of creating a system of self-surveillance, because no team members wanted to be part of a team where certain members were lagging behind. Though this could result in greater output, perhaps, it could create animosity between the team members, at the very least, a cold working environment.
- The author was at camp Yodok, he describes this as one of the nicer camps
- prisoners were separated between those who were “redeemable” and those who were “irredeemable.” Irredeemables committed, or were associated with people who at committed more serious crimes, like being a capitalist or a Christian. Redeemables were subjected to being re-educated, irredeemables were not, they did not have to learn how to praise the leader or communism because they were never going to leave the camp. 70% of Yodok prisoners were irredeemables, they suffered much worse that the redeemables which is a suffering that is difficult to imagine
- certain jobs in the camp were better than others, a few were almost even relatively tolerable
- prisoners often found themselves in the tough spot of needed to break the rules to survive and needing to obey to avoid punishment, or even, survive
- brutalities of the camp were described
- malnourishment seems to be the toughest punishment of them all
- deaths caused by the winter not common
- special grave area was dug up for room to plant corn
- when working in fields, a perk was the possibility of being able to eat insects or frogs as you found them during work
- camp snitches existed and were a valuable part of maintaining constant surveillance. The snitches were despised but were also considered victims by the inmates
- for a while, the author had the privilege of raising rabbits. The rabbits were treated very well, their furs were needed to military clothing. The meat would go to the guards but the inmates managed to keep some
- some inmates came to make rat a large part of their diet. Some inmates were inventive in capturing and raising rats. The authored ended up feeling very privileged when he was able to eat rat and stopped seeing them as something gross
- the experience has corrupted the authors world view, when he now sees vast large mountainous landscapes, he does not see beauty but is reminded of the camp's natural barriers
- basically no health services
- sometimes you could have small procedure by medical staff that is usually reserved for guards, but then often left alone to deal with infections
- prisoners often would go mad
- medical staff mostly there to determine who might get minor leniency for ailments
- propaganda sessions for adults
- minor reprieve on very special occasions including specialities like a small piece of candy or watching a propaganda film
- the author says that before the camp he loved their “leader” but says the camp “cured” him of his faith, that is, his thoughts of the leader now are all negative
- graphic public executions, from shooting or hanging, prisoners forced to stone after death
- many prisoners would be relatively numb after the first few executions
- most executions were from escape attempts
- sex forbidden
- men caught, guard or prisoner would be sent to the sweatbox, a place where people often died
- women would have to tell the village about the ordeal in great detail, as if they were telling an erotic tale
- additionally, other punishments were said to have happened such as being penetrated with garden tool spades or having breasts cut off
- sex was forbidden because these impure souls should not breed
- the brutality of the labour in part made the prison experience more tolerable in a way, because it could leave people so tired that they don't even have time or the energy to dwell on the situation. Thus, rest time could be some of the worst times, thinking about the outside world or the terrible things that have or could happen
- eventually it was time for the author and his family to leave. He was mixed on the ordeal, the camp is where he had grown up. Even though he was leaving a horrible place, he was still about to experience a drastic change and there was lots of unknown, it was even difficult to believe
- In North Korea it is very difficult, if not impossible to move up the social ladder. Children of farm peasants were condemned to be farm peasants. Non-peasants marrying peasants were forced to become peasants, since the peasants would contaminate the non-peasants.
- bribes are common in North Korea
- “The regime that never tires of denouncing capitalism has birthed a society where money is king...”
- fighting in the streets was common, people seemed to form gangs of sorts. Once the author was attacked in the street and managed to alert a police person who he had previous positive dealings with. The person who had committed the violence was sent to jail. The police allowed the author to enter the jail cell and beat the criminal, but not kill because that would cause trouble for the police. The author initially took up the offer but was soon horrified by what he was doing.
- Extensive underground network
- mail to other countries censored
- during famine, peasants began to grow crows on abandoned land as if it were their own private land. This is very against the regime but they were forced to tolerate to help limit massive starvation
- lots of North Korean families get by on money sent to them from family in Japan
- the another and his friends enjoyed listening to South Korean radio which is extremely forbidden. A friend snitched on him and he was put under surveillance. Things started getting scary, he thought he could be sent back to the camps, this time hard labour, and thus he and another friend decided it was time to try to escape North Korea all together
- the escape actually seemed relatively easy, the primary tool was bribes, the guards were paid off and guides in China helped them along.
- Unfortunately making it to the South Korean consulate did not set them home free
- apparently escape is getting easier and easier with time
- though the author had money and connections, most don't
- the two, now in China, were taken in by a Korean speaking female pimp for some time. They made good relations with the prostitution ring and eventually secured passage to South Korea.
- Getting out of China seemed even more difficult than getting out of North Korea
- more details on leaving China
- was smuggled out on a cargo ship, once in international waters the ship captain notified South Korea about the two, a S. Korean military ship came and took them
- the two amazed by how polite everyone was
- the two were interrogated for months (in a nice way) to ensure they were being truthful
- their arrival in the south was big news, though the news was sceptical of the conditions of the north
- it took about 2 years before the author could live freely, without chaperones etc. The chaperones were described as more helpful than a burden. It was tough navigating the new society after being in “...Hermit kingdom, as North Korea is sometimes called.”
- A rich businessman saw the author's story and decided to contribute money for him to go to school/re-integrate etc.
- A bank also provided a scholarship
- there was some security risk from agents from the north
- his escape probably caused problems for certain people left in the north
- often the Chinese will send back people who escape to endure certain terrible consequences
- several groups exist in the south to help people from the north
- there is human trade of women across the North Korean boarder
- food aid is tricky as it can be misused or help aid the military
- but often the military is just normal people, people often go to the military in order to get food or advance in society
- focus should be on dismantling the regime or helping escapees not on food aid
- food aid helps continue the regime
-
curl c++
Here is a code snippet I found very useful and wanted to save
// from http://www.cplusplus.com/forum/unices/45878/ #include <curl/curl.h> #include <fstream> #include <sstream> #include <iostream> // callback function writes data to a std::ostream static size_t data_write(void* buf, size_t size, size_t nmemb, void* userp) { if(userp) { std::ostream& os = *static_cast<std::ostream*>(userp); std::streamsize len = size * nmemb; if(os.write(static_cast<char*>(buf), len)) return len; } return 0; } /** * timeout is in seconds **/ CURLcode curl_read(const std::string& url, std::ostream& os, long timeout = 30) { CURLcode code(CURLE_FAILED_INIT); CURL* curl = curl_easy_init(); if(curl) { if(CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, &data_write)) && CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_NOPROGRESS, 1L)) && CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1L)) && CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_FILE, &os)) && CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_TIMEOUT, timeout)) && CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_URL, url.c_str()))) { code = curl_easy_perform(curl); } curl_easy_cleanup(curl); } return code; } int main() { curl_global_init(CURL_GLOBAL_ALL); std::ofstream ofs("output.html"); if(CURLE_OK == curl_read("http://torypages.com", ofs)) { // Web page successfully written to file } std::ostringstream oss; if(CURLE_OK == curl_read("http://torypages.com", oss)) { // Web page successfully written to string std::string html = oss.str(); } if(CURLE_OK == curl_read("http://torypages.com", std::cout)) { // Web page successfully written to standard output (console?) } curl_global_cleanup(); } -
SSH keys still asking for password
After attempting to setup an SSH key-pair for passwordless logins, I was still being asked for a password. It turns out that the remote system was taking issue with the fact that the remote user's home directory (as defined in /etc/passwd) was not in the standard /home location. After changing the home location (via /etc/passwd) they key-pair worked. I'm sure there is a way to allow for the use of a non-standard home location and SSH key-pairs, but, I worked around the issue instead.

{kind=link}
« Prev
Next »