-
Synthesis: Legal Reading, Reasoning and Writing in Canada [book notes]
- 2nd Edition
- Margaret E. McCallum
- Deborah A. Schmedemann
- Christina L. Kunz
Chapter 1
- The Lawyer's Roles
- Lawyers are advisors/advocates for their clients
- as an advocate the lawyer will, in court, defend their clients based on events of the past hoping to achieve the most fair outcome. The lawyer will also look forward in seeking the most favourable and fair outcomes for their clients
- Lawyers take life situations and frame them within legal constructs
- Process: fact investigation, research, reading the law, reasoning about the application of the law to the clients situation, writing out or orally presenting the analysis
- The skills of a lawyer are broad and encompass the skills of many other professions, ex, an "engineer's precision"
- Lawyers are also servants to the public
- Aids in the implementation of laws
- Lawyers actions in court are continuously developing Common Law
- Canadian Bar Association's Code of Professional Conduct
- The Legal System
- Local government are the creations of provincial/territorial governments and can only which they are allowed to do by their parent body
- The federal and provincial/territorial levels have three branches: legislature, judiciary, executive
- legislature makes the law
- judiciary: interperts, applies
- executive implements the law
- there is overlap between the three branches
- Aboriginals can form their own governments of sorts. Their powers of self government are a lot more broad than the powers that provincial or local governments receive.
- Rules of law exist in: cases, statues, regulations and court rules.
- Rules of law need to be predicatable
- Legal rules can be stated in an if/then format. "IF the required factual conditions exist," "THEN the specific legal consequences follow."
- factual conditions or legal consequence
- And If/Then/Unless statement can modify the If/Then situation to explain situations where the rule does not apply
- One could also say If and not some stuff Then...
- if a list uses the word "and" all elements must be fulfileld aka "conjunctive rule"
- if a list uses the word "or" at least one of the elements must be fulfilled aka "disjunctive rule"
- ex
- the person at rice, and
- the person ate
- a) an apple, or
- b) a pear, and
- the person drank water
- in the above example the person must have at rice, and either a banana or an apple, and drank water for the condition to occur.
- "And aggregate rule required you to determine whether enough of the suggested factors have been met to justify applying the legal consequences."
- that is, there will be a list of conditions that could apply, and "some" number of those conditions could be enough to trigger the legal rule
- "A balancing rule requires you to balance factors favouring either outcome in order to determine whether the legal consequences will apply."
- this could mean that there will a section that says something like, "if the harm of condition a outweighs the harm of condition b
- Aggregate and balancing rules include ambiguity which can be good or bad. It allows for flexibility but that flexibility brings along unpredictability with it.
- Plural consequences: there are multiple consequences, they are conjunctive, they use the word and, as a consequence someone might have to do this AND that.
- Alternative consequences: a consequence can be chosen from a set, the word "or" is used and is disjunctive. The person does this OR that.
- A consequence that is an ultimate practical condequence is one which directly states what the condequence is, for example, a fine
- Intermediate legal condequences might say that the consequence is an offence. One would then have to do further research to determine what is is meant by offence.
- Legal rules can be represented in charts, lists, paragraphs... one should choose the method which best depicts the rule
- administrative agencies include: boards, tribunals or commissions
- statues are used to create these, they also define their powers
- "If every statutory illegality, however trivial, in the course of performance of a contract, invalidated the agreement, the result would be an unjust and haphazard allocation of loss without regard to any rational principles." said Professor Waddams in the book, The Law of Contracts, 3rd ed. (1993) on page 381
- most cases enter the legal system at the trial court level
- some court systems force people to attempt to use alternative dispute resolution mechanisms before going to trial to attempt to resolve the issue
- A summary judgement is when a "judge decides the case based on written materials developed during discovery.."
- Appellate courts hear appeals
- "...appellate courts articulate and refine legal rules of broader application."
- "The lowest level of court in each jurisdiction is called the provincial or territorial court."
- some jurisdictions have family courts
- Superior courts are above the provincial and territorial courts
- administered by the provinces/territories
- judges appointed and paid by the federal government
- Depending where, the names: Court of Queen's (or King's) Bench, Superior Court, Supreme Court-Trial Division.
- above these in each jurisdiction is a single appellate division
- Describing the court system through text has become tiresome, here is an image taken from http://www.justice.gc.ca/eng/dept-min/pub/ccs-ajc/img/Justice-chart-eng.gif which was found here http://www.justice.gc.ca/eng/dept-min/pub/ccs-ajc/page3.html
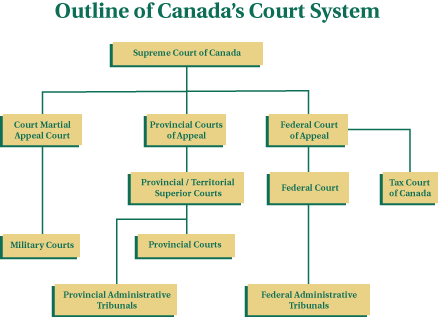
- Federal courts deal with federal matters
- Jurisdiction involves geography but also in subject matter or types of cases
- Courts have defined jurisdictions
- need "personal jurisdiction over a party based on the party's contact with the jurisdiction (in the geographic sense of the word)"
- considerations: citizenship and the place where the events occurred
- needs jurisdiction over the subject matter
- Two broad categories of court jurisdiction is general and specific (ex family court)
- court opinions operate "as law under the doctrine of stare decisis"
- "Stare decisis et non quieta movere" means "to stand by precedents and not disturb settled points."
- this helps to provide consistency in the law, that current cases which are similar to cases in the past will be resolved in similar ways.
- it also makes the court system more efficient because it means that similar cases do not need as much examination as the original case
- Of course times change, and we would not always want to be stuck with earlier decisions, and in fact we are not. The attitudes change and evolve over time. This is of particular interest to me because of my interest in Information Technology Law and because it evolves so rapidly. Judges and lawyers can find ways to differentiate what are often two very similar cases in order to set a new precedent. Appeals courts can also overrule previous precedent in order to create dramatic change.
- courts are expected to rule similar to their past decicions
- courts are bound by decisions made by higher courts in the same court system
- judges are expected to make decisions "in accordance" with previous decisions made at the same level and in the same system but are not bound by them
- decisions that courts must adhere to are considered "binding" or "mandatory" precedent
- decisions which are not binding can still be persuasive
- The Supreme Court of Canada is able to overrule its previous decisions, though this was not always the case
- newer precedents can sometimes be considered to be more persuasive
- unanimous decisions are also weighted heavier
- even the quality/thoroughness of the decisions can play a role in determining its weight as precedent
- similarity also plays a role
- sometimes precedents from entirely different countries can be considered persuasive
- there unpublished decisions and often they are not considered to form a part of common law and given substantially less weight
- Reading a case
- cases have facts, including the dispute between the parties that has led to the case and matters of law or the response of the legal system
- like reading anything else: who, what, where, when, and why are important questions to be asking yourself
- it is good to know which courts are involved, previous decisions if you are reading an appeal, who were the judges or judge, when, what are the decisions and why were they made
- the outcome of the case will serve as precedent in the future and the ruling, or the outcome teaches us a lesson: what will happen if this fact scenario occurs again?
- Format of a case:
- Citation Information: on the first or second page at the top. It "identifies where the case is published."
- Case Name (aka style of cause): in italics, identifies parties. Common party designations in a civil lawsuit: plaintiff, defendant, appellant (person bringing forward the appeal) and the respondent ("the person opposing the appeal")
- plaintiff v. defendant, but sometimes reversed on appeals
- v. stands for versus but is read "and"
- non- adversarial proceedings begin with "Re" and user "and" instead of "v."
- Criminal cases are usually R. v. the person being charged. R. stands for Rex or Regina
- Court, Judges, and Date
- Publisher's Editorial Material: sometimes called "headnotes," a bunch of words or small sentences that are used as search items. These are not written by the court and cannot replace reading the actual case
- Court's Editorial Material: sometimes a synopsis of the case may be included, but the author may have not been the judge and does not serve as a substitute to the actual case
- Authorities Referred To: other materials that the case referred to, ex, other cases or even academic texts
- Procedural History: some of the history of the case, particularly if the case is an appeal
- Lawyers for the Parties: can be helpful in obtaining further information
- Authoring Judge: Immediately before the opinion. If there is more than one judge it will be let known which ones agreed and which did not
- Opinion(s): the organization can differ from judge to judge. Usually one or more of the following occur first: "the procedure in any lower court(s) before the case reached this court, the issue(s) raised by the case, and the outcome(s)." This is followed by the facts. Most of the opinion regards the legal issues raised and the resolution of the issues. The final paragraph will have the courts conclusion/decision.
- Remedy: often in italics
- To form a "majority opinion," the one that matters most, it must have more than half of the votes.
- If a judge agrees (concurs) with the majority opinion but wishes to add their own reasons they produce what is called a "minority opinion."
- If the judge disagrees with the result they form what is called a "minority opinion."
- Sometimes there is no majority opinion because of highly diverse views among the judges.
- "the opinion drawing the largest number of votes, although less than half, is called the 'plurality opinion' and generally is viewed as the most influential of the opinions."
- this book says that one will likely have to read the case a few times in order to fully understand it
- Briefing a Case
- "A case brief is a structured set of notes on a case."
- answer the questions of who what where when and why
- what events led up to the litigation
- what is the case history, is this an appeal? What happened at the first trial? who what where when why
- what did the court(s) rule, who ruled, why did they rule in that way? who one? who lost?
- Structure
- Heading: case name, court, date, citation of the case, the judges
- the reputation of judges can impact the weight given to the decision when determining precedent
- Procedural History: who sued who, past rulings if applicable (who won and how), if this is an appeal, who won, who brought the appeal, has the case been appealed again (what is going to happen in the future)?
- Parties: not just the people but the relationships involved, ex customer of a business
- Remedy Sought:
- Facts: who what where when why. But boil it down to what is necessary.What facts must you know to understand the case? What do you need to know to understand what the court was thinking? Do provide facts that provide context. An emphasis on the facts that are needed to understand the ruling, more so than the facts which create context.
- Issue(s): The question that the court answers. "Issue = (law + facts)"
- "Substantive legal rules govern the conduct of people in the real world..."
- "procedural rules govern the conduct of litigation, that is, events in the legal system"
- some issues may be more important than others
- Holding(s): "The holding is the court's answer to the issue." Connects law to facts. Multiple holdings if multiple issues. How the dispute concludes. Holdings come in varying degrees of generality.
- Rule(s) of Law: Facts that lead to an outcome makes up a rule of law. Courts use rules of law to make a decision. These can come from various places like precedent but can even be made new if it is a new situation. If there is a new rule being created the court might signal this by stating "We thus rule..."</li>
- Reasoning (aka Application): How the rules of law applied to the case. This may include items which were considered but ultimately dismissed. It should also include the judge's sources, these sources vary importance. Sometimes a case will pivot on a source, or merely use a source to slightly bolster reasoning.
- Optional Components
- Dictum/dicta: non-essential remarks. Not considered precedent that courts can be bound by. Though these can be persuasive. Only facts that were critical to the outcome of the case can become binding precedent. Extra stuff the court thought was useful to share but was not essential to the case. This might include hypotheticals, what would have happened if the the facts were slightly different.
- Concurring and Dissenting Opinions: state them
- Questions: questions that the court have left to be resolved in the future, or questions that remain after reading the case
- All in all, provide whatever information you need to understand the case in the brief.
- multiple cases, when considered together can inform you of rules of law which would have not been apparent by if they were considered individually. one may also detect patterns by observing the results of multiple cases. perhaps the law is becoming more liberal or perhaps it is becoming more conservative.
- appeal level decisions from other jurisdictions carries more weight than an trial level decision from another jurisdiction
- when categorizing for the purposing considering multiple cases it is important to note the court hierarchy and the chronology of the cases
- track the rules of law
- read -> brief -> determine the relationships between cases
- keep in mind if the cases are binding or merely pursuasive
- arranging the cases on an organized map, or in a graphic of sort could be useful
- or since I'm a computer nerd, perhaps one day I should develop some software to do this for me
- sometimes rules may appear different from case to case, it may indeed be that the rule is changing or that certain cases only dealt with certain aspects of the rule or perhaps the rule was simply re-phrased but means the same thing
- understand the similarities and differences of rules stated in various cases.
- categories to consider: "material that is identical in all rules, material that is similar in all rules, material that appears in only some rules, or material that differs from rule to rule."
- material which is identical in all rules can be summarized into a single statement which describes them all
- some cases that are similar can be merged into the above if they wont change the result, but if they do change the result you can modify the above with conditional statements such as "unless."
- you're trying to get some sort of take away message from all this combining, and this message should not contradict its parts
- EXAMPLE of combining cases
- lets say we are considering two fictional cases
- case a: person was driving 150km/h in a 100km/h zone. Gets caught, charged and convicted.
- case b: person was driving 150km/h in a 100km/h zone. person was on their way to a hospital because a passenger was in imminent danger. The person gets caught. Had the person not had the health emergency as a mitigating factor the person would have been charged and convicted.
- when combining these two cases you can create a rule
- IF one is driving above the speed limit, THEN one is liable to be charged UNLESS it is for reasons of medical emergency.
- or
- IF one is driving above the speed limit not for the purposes of a medical emergency, THEN one is liable to be charged.
- For the record I don't believe this is actually true, call 911 instead.
- But we can see that this rule can be applied to both cases, and using the rule get to the same result as actually occurred.
- It could also be used to describe something like this with a flow chart. From the text there was a fact scenario that resulted in a chart similar to this
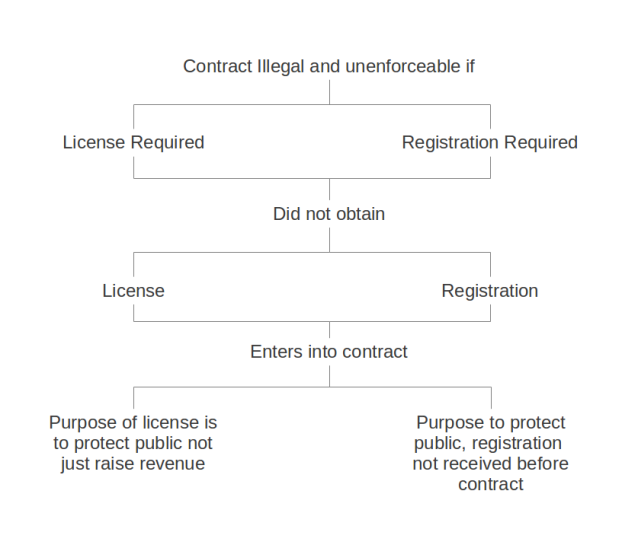 Along the left was a case where a contract was deemed unenforceable because the person completing the work did not have a license to do the work, thus the work would have been illegal and the court didn't want to support illegal work notably in this instance because the license was important to ensuring public safety. Along the right some re-wording has occurred. As depicted it shows that a contract was invalid due to illegality because of the fact that a registration was not obtained. The plaintiff was not allowed to contract for work without the registration thus technically speaking making the contract illegal. The registration like the license just discussed also serves a purpose with regards to protecting the public. However, in the actual case, the plaintiff won and the contract was enforceable even though illegal because the plaintiff practically had registered at the time and in fact did obtain the registration. At the time of contracting it appears the registration was probably in some processing queue. I believe the registration actually was granted before the work was completed and this was important in overlooking the fact that the contract was technically illegal. We can see here that this flow chart has been worded in such a way that it allows the left and the right to share the same outcome, the shared outcome of an illegal and unenforceable contract. Though the registration was received before the work was completed, the diagram has phrased it if it had not. This allows us to see the commonality in the two cases that IF a party does not have the authority to contract, THEN the contract will not be enforceable UNLESS the authority is granted before the work is completed.
Along the left was a case where a contract was deemed unenforceable because the person completing the work did not have a license to do the work, thus the work would have been illegal and the court didn't want to support illegal work notably in this instance because the license was important to ensuring public safety. Along the right some re-wording has occurred. As depicted it shows that a contract was invalid due to illegality because of the fact that a registration was not obtained. The plaintiff was not allowed to contract for work without the registration thus technically speaking making the contract illegal. The registration like the license just discussed also serves a purpose with regards to protecting the public. However, in the actual case, the plaintiff won and the contract was enforceable even though illegal because the plaintiff practically had registered at the time and in fact did obtain the registration. At the time of contracting it appears the registration was probably in some processing queue. I believe the registration actually was granted before the work was completed and this was important in overlooking the fact that the contract was technically illegal. We can see here that this flow chart has been worded in such a way that it allows the left and the right to share the same outcome, the shared outcome of an illegal and unenforceable contract. Though the registration was received before the work was completed, the diagram has phrased it if it had not. This allows us to see the commonality in the two cases that IF a party does not have the authority to contract, THEN the contract will not be enforceable UNLESS the authority is granted before the work is completed. - The lesson to take away from this is that in finding commonalities between cases one can re-work the language to better depict the the situation.
- This could possibly be thought of as rearranging formulas to fit a template.
- 1 + 2 = 3
- 1 = 3 - 2
- we can see that the second equation is in fact the exact same as the first one if we were to rearrange it.
- describing the "features" of cases and comparing them could be of use to. The way that you can, on some websites, compare the features or specifications of electronics side by side in a grid form. Some features could include: "case name, court, and year ... real-world roles of the parties, the claim (also known as 'cause of action'), the relief sought (also known as 'remedy'), the salient facts, policies stated by the court and the holding(s) of each case on the issue(s) being examined."
- look for patterns that explain the holdings
- if cases are conflicted, be sure the consider the most important cases more, such as binding ones over persuasive ones, ones from higher courts than lower, more recent versus older etc.
- sometimes cases simply cannot be combined in the way described in this chapter
- was there a radical change in the mentality of the courts, were previous decisions overruled?
- are the facts radically different? the people involved radically different? the relationship between the plaintiff and the defendant radically different?
- sometimes cases will be an outlier. Maybe for some reason a judge is unusually sympathetic to someone's cause and that sympathy leads to rule in their favour, even though, they perhaps maybe should have not.
- or perhaps a case has some highly unusual characteristic
- The purpose of this chapter was to discover methods that will help one "generate a rule or pattern that encompasses the content of many cases"
- legislation contains rules
- statues must conform with the constitution
- "...regulations made pursuant to a statute [are] called subordinate legislation"
- there are other important rules that are formed as result of Aboriginal self-government agreements
- there are also other sources of rules
- legislative process
- changes to legislation can basically come from anyone as long as they can find a way to get a member of the legislature to turn it into a bill for debate
- federal parliament = bicameral legislature
- elected house
- appointed Senate
- usually bills begin in the House of Commons, the elected house, then are passed onto the Senate. They have to gain approval from both to become law
- bills often come from cabinet ministers.
- bills can originate with any member, but have very little chance of succeeding. These are called private member' bills.
- debated etc etc (not taking notes on this)
- Interestingly however the text says this: that instead of a true debate, "[m]ore often, debate entails a series of speeches by the bill's supporters that go unheard by most of the legislators."
- lobbyists must be registered
- when a bill becomes law it is called a statute/act
- actual enactment might be delayed, this might be due to regulations being made in order to implement the act
- judicial process is intended not to be political
- legislative process is highly political
- legislative intent is a bit of a fiction since even a single piece of legislation is formed by many people and it is unlikely that they all hold the exact same intent and interpretation. Nonetheless, legislative intent is still an important concept.
- it is important that when considering statutes that you are considering the appropriate statutes for the time frame being considered. This can become more complicated when the statue has been amended several times.
- standard components of a statute
- title and citation: sometimes given a short title too. The citation includes the year the statute was passed, and the chapter which was assigned to it in the published acts for that year. The word "the" is sometimes included in the title, sometimes it is not. Bills are given names like C-X where X is the nth bill introduced in the session. Senate bills are prefixed with S rather than C. And again as with bills, X represents the nth bill for the senate during the session. X between the Commons and the Senate have NO relation. Bills often have long names. Sometimes people will continue to call what has become and Act by its C-X name.
- preamble, purpose statement: Does not always exist. This is, as obvious by its name, the purpose, why the statute exists, what is it attempting to accomplish, what issues is it attempting to address, what are the desired results. When these descriptions exist in the preamble rather than in the act they are not officially part of the act, they are just there to guide the reader and provide inferences into the intent of the act.
- Definitions: clarify technical meanings, and to narrow the definition of words. There may be multiple sections of definitions for long acts. Words may even become redefined.
- Relationships to other statutes: Generally more recent acts will overrule older acts if there is overlap or conflict. This section can make how to deal with overlap/conflict explicit. It is possible to give ultimate authority to another act.
- Power to make regulations: statues often intend that regulations will be created in order to implement the statue. The regulations will likely be created by the body which will administrate the act. In other words, legislature might delegate power to another body to make regulations
- Effective date: when the legislation becomes active. Sometimes it is necessary to do further research to determine this date. Knowing this date is important before one relies on it. An additional reason why such a delay might occur is in order to have time to inform the public about the upcoming changes in the law.
- General Rule: what the statute encourages or prohibits. This is the main part of the statute. Often there are multiple rules.
- Exceptions:
- Consequences and Enforcement: some statues require you to look elsewhere for consequences and enforcement provisions.
- Briefing a statute
- condense, make it relevant to you and if you are reading it for specific purpose, make it relevant to that purpose
- IF... THEN... can also be useful here
- plain meaning vs. purpose approach
- resolving ambiguity: "case law, indications of the legislatrue's intent, canons of construction (maxims for reading the words chosen by the legislature), and the user of similar statues and persuasive precedent."
- vague statues may have resulted because legislators were unable to agree on precise wording
- among many other reasons of course
- purposive approach: figure out what the purpose of the statue is, what "evil" or "mischief" was being corrected? Then interpret the statue in a way that is in line with correcting the evil which needed correction.
- golden rule approach: read the statue plainly unless it results in an absurd/unconstitutional result.
- With respect to interpretation the Canadian Supreme Court says, "Today there is only one principle or approach, namely, the words of an Act are to be read in their entire context and in their grammatical and ordinary sense harmoniously with the scheme of the Act, the object of the Act, and the intention of Parliament." This is called the "modern approach."
- past cases provide guidance on interpretation
- courts: provide authoritative interpretation and assess constitutionality
- statutes can be declared unconstitutional in whole or in part
- "... if the court interprets a statue in a way that the legislature did not intend, the legislature can overturn the court's decision by amending the statute. The amendments will not change the outcome for the parties to the dispute that produced the objectionable interpretation, but they will change the rule for the future."
- legislative history plays a role in helping discern legislative intent. This could includd a recommendation made by a legislative comitee, the debates had as the bill was going through the process of becoming a statue. Different aspects are considered more authoritative than others. Formal documents will be weighted heavily, so has content from the sponsors of the bill.
- "In the end, and Act means what the court says that it means, not what a member of the legislature thinks that it means."
- The legal context will also be considered when interpreting statutes. Is the statute attempting to codify what already existed in common law? Is there a pattern to be seen from reviewing the history of amendments? How do other rules of law interact with the statute in question? Is one interpretation in conflict with another rule of law while another is not? It is probably the case that legislators were aware of the constitution and did not intent to be in conflict with it.
- There are rules in each jurisdiction that set out rules on how to interpret statutes. For example, sometimes the preamble of a statue is part of the statute, in some cases it is not.
- Sometimes policy issues that existed at the time of the creation of the statute can provide interpretation guidance
- Sometimes government bodies will produce interpretation guides, this might come in the form of an FAQ. If this were to happen there is a good chance that it would come from the administrating body. The Canadian Revenue Agency might create guides in order to help people with their taxes.
- imagining a fact scenario that, or a case, that would fall right into the hands of the statute can also aid in helping interpret a case. Often it is the case that legislators are responding to incidents which have actually occurred, is it possible to guess what such an incident may have been?
- "Cannons of construction are maxims for reading and writing statues."
- unless defined, words should be interpreted in there every day meanings.
- "Ejusdem Generis:" "of the same class." For example, if the statue lists several documents relating to real property, then has a catch all at the end that says something like "and any other document" it is to be understood that this would be any other document about real property, that is, in the same class as the documents which were explicitly listed.
- Specific items take prevalence over general. If there is a conflict in rules, the more specific one would more likely to be considered to of precedence.
- Provisions enacted later (the newest ones/the most recent ones) take precedence over provisions that were enacted earlier
- "Expressio Unius:" "expressio unius est exclusio alterius" if there is a lit of items, and there isn't a specific catch all like "any other documents" only the items on the list are included.
- It should be assumed that all language is there to add something. If something could be interpreted as meaningful or completely non-meaningful, it should be considered to be meaningful. If all items in a statute are all given a penalty, the same penalty, for example, then in one part of the statute it speaks of a penalty to be had for a specific action, this penalty should be considered in addition to the blanket penalty which has already been established for all aspects of the statute. The fact that the statute states a penalty for a specific part of the statute could be considered non-meaningful since it overlaps with what has already been established, but this is not the norm in which should be used to interpret statute. Or, just because the there are variable rate charges on your taxi cab fare, it does not mean that the fixed rate charge is no long there.
- "In Pari Materia:" "of the same matter" if there is more than one statute on the same topic they should be considered together. A manifestation of this is that if a word is defined in one and not the other, there may in fact be a definition for both as a result.
- interpretation of criminal laws should be done narrowly
- using persuasive opinions from other jurisdictions is more likely to occur if the relevant law in the persuasive jurisdiction is modelled from a common source as the relevant law where the decision is being made. Based on my memory, this could happen for instance with PIPEDA and related law as PIPEDA serves as a model law which the provinces themselves are supposed to eventually implement.
- commentary is just that, it is not law, it is not absolutely authoritative but it can help in furthering your understanding of the law
- always check that lower court decisions have not changed on appeal
- was the case you are investigating later used/referenced as precedent setting?
- Recording your bad search methods van be handy in making sure that you don't repeat your past failed attempts
- commentary should be used to supplement your legal understanding not supplant it.
- deductive reasoning: apply elements of law to a real case.
- reasoning by example: compare facts of a case yet to be resolved to a similar case which has been resolved
- the rest of this chapter pertains to deductive reasoning
- use legal rules to predict the outcome of cases
- align case facts with legal rule requirements
- sometimes assumptions will be required to make a legal analysis. Since assumptions are not certain, it may be beneficial to consider the outcomes based on various assumptions
- a chart can be used in helping analyse of the facts of the case you are analysing relates to the law. A sample of this could look like this.
element case facts element met? IF List the legal elements required list how the elements relate to the facts of the case has it been met? THEN list the legal consequences list how it relates to the case - if elements of a legal rule are not met in a case being analysed it sometimes can be useful to restate the legal rules in their negative IF THEN form.
- IF 1 and 2 would become IF not 1 or 2
- IF 1 or 2 would become IF not 1 and 2
- the same transformation would happen with the THEN portion
- drawing on analogy
- distinguishing cases
- the degree to which a case can be distinguished can suggest the degree to which the result may or should differ
- two important criteria in order to be able to use a case as an example
- needs to address the same, or very similar legal rule
- facts should be similar or same, the facts relevant to the legal rule are the most important
- some similarities and differences are more important than others
- the narrowness or the generalness of the case in which you are comparing to can guide how narrow or general your interpretation should be
- intentionality incorrectly interpreting overly narrow or broad in or to find a favourable result is unlikely to be adventageous
- Venn Diagrams to show similarities and differences
- reasoning by example cannot be used alone but supplements deductive reasoning
- policy analysis
- it may be the case that deductive reasoning and reasoning by example may not be enough
- broad society goal of laws
- policy often drives law
- considers society's interests
- based on conceptions of societal good
- could be called: legislative, government, or social policy. Is NOT "public policy"
- Public policy: "... a term of art used to identify the basis on which judges can refuse to enforce contracts or conditions attached to land transfers if they are against the good of the community or contrary to established conceptions of justice and morality."
- policy is tricky and often doesn't do a very good job of representing everyone. It is often one sided.
- stakeholder analysis can be performed here
- understand policy behind law and apply it to cases, what was the goal of the law and how does it relate to the case?
- if there is more than one policy at play, is one more important than another?
- dose one outcome of the case better serve a policy more than another?
- what outcome would result in the greatest amount of policy being served?
- Reader-Centred Writing
- when writing, take into account the characteristics of the reader
- keep to relevant points
- consider how the reader will actually go through the paper, are they likely to skim?
- What does the reader already know?
- What does the reader still need to know?
- Legal writing has specific conventions
- following these are important for many reasons including maintaining professional credibility
- legal writing is formal
- should not contain first person
- for one, it gives a more objective appearance
- Function / Format of legal memo
- aka file memo, intraoffice memo, or internal memo
- good if there is more than one lawyer involved
- can contain all sorts of information, anything that needs to be communicated
- analytical memo
- records known facts
- documents research
- sets of reasoning
- predictions of resolution
- strategy
- don't forget that the memo might be referenced in the future for similar cases
- the writer is also likely to be an audience for the memo
- common memo components
- caption: recipient's name, writers name, date, subject (client's name, file number, brief description).
- Issue(s): the legal issue
- Short Answer(s): provides the writer's position on the legal issues. Provides bottom line answers.
- Facts: The client story. If the whole story is not known it may discuss the future
- Discussion: This makes up the majority of the memo. Intro, presentation of rule of law, application of rules to facts, conclusion.
- Conclusion / Recommendations
- appendices
-
Problems Un-mounting
I had some problems un-mounting an sshfs mount. I did a "umount -fl" (force, lazy) and tried re-mounting, but I continued to have issues. I fixed the issue with a combination of un-mounting and clearing the mount entry from /etc/mtab which entailed simply opening /etc/mtab in a text editor and removing the relevant line entry.
-
Toronto Snow Day 2013
It's like Toronto has never seen snow before. Here is my take on the day.










-
POCO Install/Compile Error Fix
I was in the process of installing the POCO Libraries on Ubuntu 12.10 for C++ and while compiling I received this error: ODBC.make:49: *** No ODBC library found. Please install unixODBC or iODBC or specify ODBCLIBDIR and try again. I fixed it with:
apt-get install unixodbc-dev libmysqlclient-dev -
Remove Youtube Comments
I recently wrote a Python 3.2 script which will remove your Youtube comments automatically for you. It works reasonably well, but it did require me to run it a few times in order to get everything. It uses the Google/Youtube API to accomplish the deletion, but some "hackery" was needed in order to find the comments which need to be deleted. This "hackery" entails scraping Google web search results, something which is not entirely kosher. As such, you may find that Google will temporarily block your requests being made from this script, as they did to me at one point. This is fine because the proper method of access Google search remained open and I was in no rush since this is just for personal use, so I just waited it out. I have since inserted a delay command in the script to make the requests look a little more human like, but of course that does cause the script to take longer. I have not included the Google app id I used to run this script, you will have to create your own at https://code.google.com/apis/console/. You will also have to update the script to use your own Youtube username. The places in the code that require your attention most have exclamation marks in the comments. I used this script on Ubuntu 12.10 with curl installed. The script has been formatted for this blog, if an error arises it may be around a long string that was made to occur on multiple lines after the fact.
import lxml.html import urllib.request import urllib.parse import json import webbrowser import time import sys import subprocess ##### get authenticated ##### client_id = "847147874147.apps.googleusercontent.com" ## need to get your own !!!!!!!!! client_secret = "92dGuyKje6DncGo8EOe8GYKJ" ## need to get your own !!!!!!!!! apiKey = "MIzjSyQmSZ3U18vmD1esxF-gQU2ZmXKdf5FQoCW" ## need to get your own !!!!!!!!! url = "https://accounts.google.com/o/oauth2/auth?client_id=" +\ "{0}&response_type=code&scope=https://www.googleapis.com/auth/youtube".format(client_id) +\ "&redirect_uri=urn:ietf:wg:oauth:2.0:oob" webbrowser.open(url) time.sleep(2) # required for clean output display code = input('paste in your code: ') values = {"code" : code, "client_id" : client_id, "client_secret" : client_secret, "grant_type" : "authorization_code", "redirect_uri" : "urn:ietf:wg:oauth:2.0:oob"} url = "https://accounts.google.com/o/oauth2/token" data = urllib.parse.urlencode(values).encode('utf-8') request = urllib.request.Request(url, data=data,\ headers={"Host": "accounts.google.com",\ "Content-Type": "application/x-www-form-urlencoded"}) try: page = urllib.request.urlopen(request) except: print("Was not able to authenticate, quitting.") sys.exit(0) authJson = json.loads(page.read().decode('utf-8')) access_token = authJson['access_token'] refresh_token = authJson['refresh_token'] #unused if not access_token: print ("was not able to authenticate, quitting.") sys.exit(0) ########## get links from google ######### username = "INSERT_YOUR_USERNAME_HERE!!!!!!!!!!!!!" ## !!!!!!!!!!!!!!!!!! query = "site:youtube.com%2Fall_comments+-site%3Am.youtube.com%20" + username start = 0 #page count, goes by 10s user_agent = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.20' +\ ' (KHTML, like Gecko) Ubuntu/12.04 Chromium/18.0.1025.168 Chrome/18.0.1025.168 Safari/535.19' linkArray = [] while True: url = "https://www.google.ca/search?q=" + query + "&start=" + str(start) page = urllib.request.urlopen(urllib.request.Request(url, headers={'User-Agent': user_agent})) pageStr = page.read().decode('utf-8') html = lxml.html.fromstring(pageStr) result = html.xpath('//a[@class="l"]') if not result: break; else: start = start + 10 time.sleep(10) # be nice to google for i in result: link = i.get('href') linkArray.append(link) ###### get comment ids ###### commentLinkArray = [] for i in linkArray: try: videoId = i[38:] url = "http://gdata.youtube.com/feeds/api/videos/{0}/comments?alt=json".format(videoId) commentJson = json.loads(urllib.request.urlopen(url).read().decode('utf-8')) for x in commentJson['feed']['entry']: if x['author'][0]['name']['$t'] == username: print ("sssss") commentLinkArray.append(x['link'][2]['href']) except: pass ##### Perform the deletion ###### for i in commentLinkArray: print ("Deleting:", i) call = ["/usr/bin/curl", "-X", "DELETE", "{0}".format(i), "-H", "Authorization: Bearer {0}".format(access_token), "-H", "X-GData-Key: key={0}".format(apiKey), "-H", "GData-Version: 2", "-H", "Content-Type: application/atom+xml", "-H", "Host: gdata.youtube.com", "-o", "/dev/null"] ## not sure if this did anything subprocess.call(call) -
redshift / gtk-redshift wont start
In my Ubuntu 12.10 install redshift / gtk-reshift would not start. When ran from the terminal the following is the output that I would receive:
Started Geoclue provider `Geoclue Master'. Using provider `geoclue'. ** (process:911): WARNING **: Could not get location, 3 retries left. ** (process:911): WARNING **: Could not get location, 2 retries left. ** (process:911): WARNING **: Could not get location, 1 retries left. ** (process:911): WARNING **: Provider does not have a valid location available.It seems to be looking for something which determines my current geo coordinates and failing to find it. With the -l switch you can supply your coordinates manually. You can get your coordinates by googling "your city longitude latitude." In order for you to be able to open Redshift from the Unity dash with this switch / manual entry, you need to update the launcher file for the application. As root I updated the exec value of /usr/share/applications/gtk-redshift.desktop to be "Exec=gtk-redshift -l 43:79" and my problem was solved.
-
Python3 - all threads complete, return data example
This is simply a demonstration of threading in Python. In addition to threading it also has awareness of when the threads are complete and be able to return data. Code:
#!/usr/bin/env python3 import time, threading, queue def print_t(name, delay, q): q.put("I am data from " + name) for i in range(1,10): time.sleep(delay) print (name) q1 = queue.Queue() q2 = queue.Queue() t1 = threading.Thread(target=print_t, args=("First Thread", 1, q1)) t2 = threading.Thread(target=print_t, args=("Second Thread", 2, q2)) t1.start() t2.start() t1.join() print ("First Thread complete") t2.join() print ("All Threads complete") print (q1.get()) print (q2.get())Output:
First Thread First Thread Second Thread First Thread First Thread Second Thread First Thread First Thread Second Thread First Thread First Thread Second Thread First Thread First Thread complete Second Thread Second Thread Second Thread Second Thread Second Thread All Threads complete I am data from First Thread I am data from Second Thread -
Facebook + webclient + xmpp
I don't necessarily like how we are becoming as dependant on web services as we are. Perhaps I have some tinfoil hat syndrome symptoms, but putting total control in other people's hands doesn't seem right. Web services certainly have their place, and I will certainly continue to use them, but where possible and appropriate, it would be nice to take control again. The decision, in part, depends on expectations. Some things are meant to be public, or there is an expectation that certain actions might be public or not totally private, and in these scenarios, web services are more appropriate. Given this idea of when web services are appropriate, it seems to me that instant messaging is a place where the user should have a fair amount of control. The things I say in an instant messaging session are things that I expect to be between me and the other party or parties whom I know are involved. This is why I am becoming uncomfortable with Facebook chat. Comparatively, unlike with other uses of Facebook, I am not comfortable with my instant messages being data mined. As such, I wanted to see if there is a way where I could reduce my dependence on Facebook chat.
My idea is that I could create an alternative way for people to contact me. The alternative should be easy to use as to not burden the user attempting to contact me. It must to a degree, integrate with Facebook since that is where people are, and that is how people would often attempt to start an instant messaging session with me. Some Facebook integration would reduce the need for people to register entirely new accounts, and put up with the hassle of doing so. It also serves as a great way for me to authenticate who they are. If users were registering new accounts, I would have to take it on faith that they are who they say they are. By linking with Facebook I get the assurance that the person I am communicating with, is the person behind the Facebook account which I have grown to trust. Now, of course this creates the possibility that someone has been a fraud for many years, but, there is only so much I can do.
To accomplish this, I set out to create a web XMPP client which could use Facebook authentication which would then communicate with my XMPP instant messaging account. The rest of this post will detail many of the experiences I had. It will include much if not all of the code to make this happen, however the code will be altered at times for this post. The code isn't final and I don't consider it to be of production quality but it does get the job done, and for personal experiments, this is often good enough.
 The diagram here is meant to give a general overview of what is going on. It isn't a super precise diagram, I only included the details that I thought were important. There are also certainly important aspects which I have chosen to entirely not include, like third-party libraries that serve as key components to the system. The numbers listed, do not necessarily indicate the order in which items are processed.
The diagram here is meant to give a general overview of what is going on. It isn't a super precise diagram, I only included the details that I thought were important. There are also certainly important aspects which I have chosen to entirely not include, like third-party libraries that serve as key components to the system. The numbers listed, do not necessarily indicate the order in which items are processed.- Actual movement between pages occurs here. If the user is not logged in they are redirected to Facebook.
- User is sent back, index.php is reloaded but this time being logged in.
- Creates user if does not exist.
- Web browser moves to a new webpage. Also sends Facebook user ID.
- chat.py instantiates a listener
- When listener receives a message it writes in the chat log.
- chat.py includes chat.js
- When the message button on chat.py is pressed chat.js pushes the message to send.py so that it can sent.
- Periodically chat.js checks with chatReader.py to see if there are new messages to display.
- chatReader.py monitors the chat log to see if there is anything new.
- Periodically chat.js tells pidAlive.py that the session is still open.
- pidAlive.py makes note of the fact that the session is still alive.
- chat.py includes style.css.
- cron periodically run pidKiller.py
- pidKiller.py checks with PID records to see the status of chat sessions.
- Upstart tells fbReplyBot.py to run.
index.php
index.php is the landing page for the web application. This is the first page that people will reach when visiting the web application. My preference would have been to use Python for the entire application, but due to the fact that this part of the application requires access to the Facebook API it was easier for me to simply use PHP here. This was in part because I have worked with the PHP Facebook API before. I know there is the unofficial Python Facebook API and in fact I have used it before, and it works well, but not in a web setting. I am only thinking about it now, but there is also the Facebook Javascript API which perhaps could have been used. This is something to consider for a hypothetical version 2. But as I have mentioned a few times on this blog, I don't know Javascript, I just use it from time to time. The frequency that this happens make me think I should just learn the basics.
In the usual new user process, the user comes to the page and is redirected to a login page controlled by Facebook. The user is then redirected back to this page, however, this time they are logged in. Each and every person who uses this application becomes registered with my local Openfire XMPP server. The user is not aware of this fact. The user's Openfire account is linked with their Facebook account. If the Facebook account has not already been linked to an Openfire account, the link will be made, if so, this linking process will be skipped over. The final function of this script is to notify the user of the consequences of me using a self-signed SSL certificate. Ultimately, potentially scaring some people with the self-signed certificate is better than not using SSL and is better than me paying the money to get a proper certificate. This part of the program also showed me how to do some browser detection.
<?php require './facebook-php/src/facebook.php'; // setting info for Facebook application $facebook = new Facebook(array( 'appId' : '222', 'secret' : '22', )); // Get User ID $user = $facebook->getUser(); // We may or may not have this data based on whether the user is logged in. // // If we have a $user id here, it means we know the user is logged into // Facebook, but we don't know if the access token is valid. An access // token is invalid if the user logged out of Facebook. if ($user) { try { // Proceed knowing you have a logged in user who's authenticated. $user_profile = $facebook->api('/me'); } catch (FacebookApiException $e) { error_log($e); $user = null; } } // if user is logged in if ($user) { // check if not registered // register $fbId = $user_profile['id']; $fbFname = $user_profile['first_name']; $fbLname = $user_profile['last_name']; $fbName = "$fbFname%20$fbLname"; // generate password for user $password = censored $secret = "censored"; // attempt to make new account on openfire server // the line below requires the User Service plugin on Openfire $url = "http://censored:9090/plugins/userService/userservice? \ type=add&secret=$secret&username=fb_$fbId&password=$password&name=$fbName"; $curl_handle = curl_init(); curl_setopt( $curl_handle, CURLOPT_URL, $url ); curl_setopt( $curl_handle, CURLOPT_RETURNTRANSFER, true ); // Fetch the contents too $html = curl_exec( $curl_handle ); // Execute the request curl_close( $curl_handle ); $onlyGet = //security mechanism for maintaining session, sort of like a token $toPost = array( "fbId" : $fbId, "fbName" : "$fbFname $fbLname", "onlyGet" : $onlyGet ); // The block directly below doesn't really matter and I could // probably remove it except maybe the last else. Whether the // user already exists or doesn't, it doesn't really change // anything. The final else could be important because unlike // with the first two, there is no user at this point, and // the rest of the application will not work. As I am // preparing this for the web, I am thinking I will just // redirect the user to a generic error page. I am not too // concerned about this, because the chances of the final if // statement being triggered is unlikely. if (trim($html) == "<result>ok</result>"){ //header("location:$chatUrl"); //do nothing } elseif (trim($html) == "<error>UserAlreadyExistsException</error>") { //header("location:$chatUrl"); //do nothing } else { echo "I don't really know what happened..."; // in hindsight, I probably forgot to address this. Job for V2 } } else { // not logged in, go to facebook to login $loginUrl = $facebook->getLoginUrl(); header("Location:$loginUrl"); } ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html> <head> <style> // deleted to save space </style> <script src="jquery-1.8.3.min.js"></script> <script language="JavaScript"> // lesson on browser detection $(document).ready(function(){ var isChrome = /Chrome/.test(navigator.userAgent) \ && /Google Inc/.test(navigator.vendor); var isSafari = /Safari/.test(navigator.userAgent) \ && /Apple Computer/.test(navigator.vendor); if ($.browser.mozilla == true){ $("#chrome").hide(); $("#safari").hide(); $("#ie").hide(); $("#opera").hide(); } else if (isChrome){ $("#firefox").hide(); $("#safari").hide(); $("#ie").hide(); $("#opera").hide(); } else if (isSafari){ $("#firefox").hide(); $("#chrome").hide(); $("#ie").hide(); $("#opera").hide(); } else if ($.browser.opera == true){ $("#firefox").hide(); $("#chrome").hide(); $("#ie").hide(); $("#safari").hide(); } else if ($.browser.msie == true){ $("#firefox").hide(); $("#chrome").hide(); $("#opera").hide(); $("#safari").hide(); } }); </script> </head> <body> <!-- warn people about the self signed certificate --> <div id="notice"> Please be advised that you will likely have to allow for security exception as described below, <a href="#" onclick="document.frm.submit();">click here to continue</a>. </div> <div id="chrome"> <h1>Chrome</h1> <img src="images/chromeWarn1.png" /> </div> <div id="firefox"> <h1>Firefox</h1> <img src="images/ffWarn1.png" /> <img src="images/ffWarn2.png" /> <img src="images/ffWarn3.png" /> </div> <div id="safari"> <h1>Safari</h1> <img src="images/safari.png" /> <div id='original'> This image originally appeared at http://magma.maths.usyd.edu.au/magma/faq/sslcertificate </div> </div> <div id="opera"> <h1>Opera</h1> <img src="images/operaWarn.png" /> </div> <div id="ie"> <h1>Inernet Explorer</h1> Okay, I really wasn't in the mood to accommodate Internet Explorer, so just go <a href="http://magma.maths.usyd.edu.au/magma/faq/sslcertificate#sec_5"> here</a> if you need information on it, or just go <a href="http://www.google.com/chrome">here</a> and save yourself. </div> <form action='https://example.com/webxmpp/chat.py' method='post' name='frm'> <?php //just a way to pass on some data to the next page foreach ($toPost as $name : $value) { echo "<input type='hidden' name='".$name."' value='".$value."'>"; } ?> </form> </body> </html>chat.py
This is really the main part of the application. It is the final destination for a user's web browser and where the chat session occurs. But of course this script connects to other scripts which in turn connect to even more scripts and so on and so forth.
The first thing the script does is receive information sent to it from index.php. It then deals with the handling of listener.py. Every chat session needs an instance of listener.py because this is how messages are received, it listens for messages that are sent to it, that is, specifically, it listens for messages that I send from my XMPP client back to the web client application (the system being described in this blog post). Though, perhaps the situation is better described by saying that every active user needs one instance of listener.py, if there are multiple windows open to the chat application, there is still a need for only one instance of listener.py. The second function this script performs is the handling of listener.py instances. It checks to see if any existing listener.py instances are active, and if not it starts one.
Every instance of listener.py is represented by Linux/the operating system by a Process ID, a PID. This application keeps track of the PID, which user created the PID, and whether the user still has chat windows open that require listener.py. It does this by creating a file in "./pids/" for each instance of listener.py using the PID as the filename. Within each of these files, labelled with the PID of the listener.py instance has a user ID on the first line, and a timestamp on the second line. With all this information I can know what instances of listener.py are active, who owns them, and whether it is time to close the instance. Knowing the ownership of the listener.py instances, or the ownership of the PIDs at this point is important because if the application finds that there is already an active listener.py instance for the user it will not create a new one.
Finally, the code below provides the necessary HTML for the chat window as well as providing some hidden form fields in order to facilitate the movement of data between other parts of the application.
#!/usr/bin/python3.2 print ("Content-Type: text/html") print ("") import cgi import cgitb; cgitb.enable() import hashlib import subprocess import time import os # accept data from index.php formData = cgi.FieldStorage() fbId = formData.getvalue("fbId") fbName = formData.getvalue("fbName") onlyGet = formData.getvalue("onlyGet") # security mechanism, the expected value should be one of the values on index.php onlyGetExpected = censored if onlyGetExpected == onlyGet: password = # openfire user password jstoken = # a token of sorts pidToken = # another token # check for existing listeners doesPidExist = False for root, dirs, files in os.walk("./pids/"): for pidFileName in files: pidFile = open("./pids/" + pidFileName) lines = pidFile.readlines() pidToken2 = lines[0][:-1] if pidToken == pidToken2: doesPidExist = True listenPid = pidFileName jid = censored + "@xmpp.example.com" # create a listener.py instance using subprocess.Popen # TODO: fix the fact that this path will not tolerate # the application being moved. if doesPidExist == False: listener = subprocess.Popen(['python3.2', \ '/var/www/webxmpp/listener.py', '-j', jid,\ '-p', password], stdout=subprocess.PIPE,\ stderr=subprocess.STDOUT) listenPid = listener.pid f = open("./pids/" + str(listenPid), 'w') toWrite = pidToken + "\n" + str(time.mktime(time.gmtime())) f.write(toWrite) f.close() print(""" <html> <head> <link type="text/css" rel="stylesheet" href="style.css" /> <script src="jquery-1.8.3.min.js"></script> <script language="JavaScript" src="chat.js" ></script> </head> <body> <div id="chatbox"></div> <form name="message" action=""> <input name="usermsg" type="text" id="usermsg" size="63" /> <input name="submitmsg" type="submit" id="submitmsg" value="Send" /> <!-- the rest is data I need to share with other --> <!-- parts of the system --> <input name="jsfbid" id="jsfbid" type="hidden" value="%(fbId)s" /> <input name="jsjid" id="jsjid" type="hidden" value="%(jid)s" /> <input name="jsname" id="jsname" type="hidden" value="%(jsname)s" /> <input name="jstoken" id="jstoken" type="hidden" value="%(jstoken)s" /> <input name="jspid" id="jspid" type="hidden" value="%(jspid)s" /> </form> </body> </html> """ % dict(fbName=fbName, fbId=fbId, jid=jid, jsname=fbName, jstoken=jstoken, jspid=listenPid)) # the line above actually shows a pretty neat way of including data # inside a large string. You'll be able to see the dictionary keys # are dispersed through the python string else: # invalid token of sorts print ("something went wrong") #someone might actually be cheating!chat.js
This is the Javascript file that accompanies chat.py. It runs several pieces of code periodically feeding information to and from chat.py and the chat window contained within chat.py and other parts of the application. It facilitates the sending of a message when a message is typed and the send button is clicked by taking what is in the new message box located on chat.py and sending it to send.py which will be explained later. This script also monitors the chat log and continuously updates the chat window in chat.py with the chat log's contents. The chat log contains the entire chat. Not only does it contain the entire chat, it contains everything that is inside the chat window in chat.py. In this case, the chat window is specifically referring to the portion of the screen where all previous messages are displayed. And it containing everything that is in the window, also means that it includes HTML. The chat log is not simply just text, but a mixture of text and HTML. The final function of chat.js is to inform the system that listener.py instances should stay alive. It does this by periodically calling pidAlive.py which updates the timestamp of the appropriate PID record located in "./pids/" as mentioned earlier.
// jQuery Document $(document).ready(function(){ //If user submits the form $("#submitmsg").click(function(){ var clientmsg = $("#usermsg").val(); var jsfbid = $("#jsfbid").val(); var jsname = $("#jsname").val(); var jstoken = $("#jstoken").val(); var forAjax = {text: clientmsg, fbid: jsfbid, jsname: jsname, jstoken: jstoken}; // submit data to the send script $.post("send.py", forAjax); // clear the chatbox $("#usermsg").attr("value", ""); return false; }); //Load the file containing the chat log into the chatbox function loadLog(){ //var menuId = $("ul.nav").first().attr("id"); var jstoken = $("#jstoken").val(); var jsfbid = $("#jsfbid").val(); var request = $.ajax({ url: 'chatReader.py', type: "POST", data: {jsjid : $('#jsjid').val(), jstoken: jstoken, jsfbid: jsfbid}, dataType: "html" }); request.done(function(html) { var oldHeight = $('#chatbox')[0].scrollHeight; $("#chatbox").html(html) $(function() { var height = $('#chatbox')[0].scrollHeight; if (oldHeight != height){ $('#chatbox').animate({scrollTop: height}); } }); }); } setInterval (loadLog, 1000); // every second function keepalive(){ var jsfbid = $("#jsfbid").val(); var jspid = $("#jspid").val(); var forAjax2 = {fbid: jsfbid, pid: jspid}; $.post("pidAlive.py", forAjax2); } setInterval (keepalive, 180000) // every 3 minutes });send.py
The code in this file has been adapted from here. I have left many of the original comments intact. This script takes a message and sends it to my XMPP client (not the application being described in this blog post) and makes an entry in the chat log.
#!/usr/bin/python3.2 print ("Content-Type: text/html") print ("") import cgi import cgitb; cgitb.enable() import sleekxmpp import hashlib class SendMsgBot(sleekxmpp.ClientXMPP): def __init__(self, jid, password, recipient, message): sleekxmpp.ClientXMPP.__init__(self, jid, password) # The message we wish to send, and the JID that # will receive it. self.recipient = recipient self.msg = message # The session_start event will be triggered when # the bot establishes its connection with the server # and the XML streams are ready for use. We want to # listen for this event so that we we can initialize # our roster. self.add_event_handler("session_start", self.start) def start(self, event): """ Process the session_start event. Typical actions for the session_start event are requesting the roster and broadcasting an initial presence stanza. Arguments: event -- An empty dictionary. The session_start event does not provide any additional data. """ self.send_presence() self.get_roster() self.send_message(mto=self.recipient, mbody=self.msg, mtype='chat') # Using wait=True ensures that the send queue will be # emptied before ending the session. self.disconnect(wait=True) if __name__ == '__main__': # get the information sent by chat.js form = cgi.FieldStorage() message = form.getvalue("text") fbId = form.getvalue("fbid") fbName = form.getvalue("jsname") jsToken = form.getvalue("jstoken") jstokenExpected = censored if jsToken == jstokenExpected: jid = censorredUserName + "@xmpp.example.com" # write to the chatlog f = open('./chats/' + jid, 'a') f.write(fbName + ": " + message + "") f.close() password = censored to = censoredMeTory message = fbName + ": " + message xmpp = SendMsgBot(jid, password, to, message) xmpp.register_plugin('xep_0030') # Service Discovery xmpp.register_plugin('xep_0199') # XMPP Ping if xmpp.connect(): xmpp.process(block=True) print("Done ") else: # this is pretty useless. I should consider writing this # error to the chat log. print("Unable to connect.") else: print ('error') #shady business, bad tokenchatReader.py
This script will be called by chat.js. It reads the contents of the chat logs and outputs back their contents. It would technically be possible for chat.js to read the chat log directly, but this extra step is necessary for security purposes.
#!/usr/bin/python3.2 print ("Content-Type: text/html") print ("") import cgi import cgitb; cgitb.enable() import hashlib import os # get data sent by chat.js form = cgi.FieldStorage() jsjid = form.getvalue("jsjid") token = form.getvalue("jstoken") fbid = form.getvalue("jsfbid") tokenExpected = censored # simple read and output the chat file assuming security requirements are met if token == tokenExpected: if os.path.isfile('chats/' + jsjid): f = open('chats/' + jsjid, 'r') lines = f.readlines() for line in lines: print (line) else: print ("no chatting yet")pidAlive.py
This interacts with the PID records stored under "./pids/" by updating their timestamp. It takes the contents of the PID record and re-writes them with the updated timestamp. This script is ran periodically by chat.js. Without this, listener.py instances would be killed by pidKiller.py even if the browser is still open with the chat session.
#!/usr/bin/python3.2 print ("Content-Type: text/html") print ("") import cgi import cgitb; cgitb.enable() import hashlib import os import time form = cgi.FieldStorage() pid = form.getvalue("pid") fbId = form.getvalue("fbid") pidTokenExpected = censored if os.path.isfile("./pids/" + pid): f = open("./pids/" + pid, 'r') lines = f.readlines() token = lines[0][:-1] f.close() if token == pidTokenExpected: toWrite = "" + token + "\n" + str(time.mktime(time.gmtime())) f = open("./pids/" + pid, 'w') f.write(toWrite) f.closepidKiller.py
This is ran periodically by cron. It looks through all the files in "./pids/" which represent active instances of listener.py. If the timestamp in the PID record is too old, it kills the instance of listener.py associated with the PID and removes the PID record. It checks to make sure that the PID it is about to kill is actually associated with an instance of listener.py to make sure that other system processes are not inappropriately killed. If somehow there is a PID record of a non-existent PID, the PID record is still removed.
#!/usr/bin/python3.2 # this should be on a cronjob for every 5 minutes import time import os from subprocess import Popen, PIPE # need this because we are running with cron myPath = os.path.dirname(os.path.abspath(__file__)) for root, dirs, files in os.walk(myPath + "/pids/"): for f in files: if f == '.htaccess': continue pidFile = open(myPath + "/pids/" + f) lines = pidFile.readlines() stamp = lines[1] currentTime = time.mktime(time.gmtime()) delta = float(currentTime) - float(stamp) if delta &gt; 4*60: p = Popen('ps -p '+ f +' -o cmd', shell=True, stdout=PIPE, stderr=PIPE) out, err = p.communicate() command = out[4:37].decode("utf-8") os.remove(myPath + "/pids/" + f) expectedCommand = "python3.2 "+ myPath + "/listener.py" if command == expectedCommand: Popen(['kill', f])fbReplyBot.py
The code below is nearly a one-to-one duplicate of this. Originally the code received XMPP messages and sent what was received back to the sender. In this case, the code receives messages and then sends back a reply with instructions on how to use the application described in this blog post.
#!/usr/bin/python3.2 # -*- coding: utf-8 -*- """ SleekXMPP: The Sleek XMPP Library Copyright (C) 2010 Nathanael C. Fritz This file is part of SleekXMPP. See the file LICENSE for copying permission. """ # http://en.wikipedia.org/wiki/MIT_License import os import sys cmd_folder = os.path.dirname(os.path.abspath(__file__)) if cmd_folder not in sys.path: sys.path.insert(0, cmd_folder) import logging import getpass from optparse import OptionParser import sleekxmpp # Python versions before 3.0 do not use UTF-8 encoding # by default. To ensure that Unicode is handled properly # throughout SleekXMPP, we will set the default encoding # ourselves to UTF-8. if sys.version_info < (3, 0): reload(sys) sys.setdefaultencoding('utf8') else: raw_input = input class EchoBot(sleekxmpp.ClientXMPP): """ A simple SleekXMPP bot that will echo messages it receives, along with a short thank you message. """ jid = "" def __init__(self, jid, password): sleekxmpp.ClientXMPP.__init__(self, jid, password) # The session_start event will be triggered when # the bot establishes its connection with the server # and the XML streams are ready for use. We want to # listen for this event so that we we can initialize # our roster. self.add_event_handler("session_start", self.start) # The message event is triggered whenever a message # stanza is received. Be aware that that includes # MUC messages and error messages. self.add_event_handler("message", self.message) self.jid = jid def start(self, event): """ Process the session_start event. Typical actions for the session_start event are requesting the roster and broadcasting an initial presence stanza. Arguments: event -- An empty dictionary. The session_start event does not provide any additional data. """ self.send_presence() self.get_roster() def message(self, msg): """ Process incoming message stanzas. Be aware that this also includes MUC messages and error messages. It is usually a good idea to check the messages's type before processing or sending replies. Arguments: msg -- The received message stanza. See the documentation for stanza objects and the Message stanza to see how it may be used. """ if msg['type'] in ('chat', 'normal'): # tell people to use this application msg.reply("Thanks for contacting me, ...").send() if __name__ == '__main__': # Setup the command line arguments. optp = OptionParser() # Output verbosity options. optp.add_option('-q', '--quiet', help='set logging to ERROR', action='store_const', dest='loglevel', const=logging.ERROR, default=logging.INFO) optp.add_option('-d', '--debug', help='set logging to DEBUG', action='store_const', dest='loglevel', const=logging.DEBUG, default=logging.INFO) optp.add_option('-v', '--verbose', help='set logging to COMM', action='store_const', dest='loglevel', const=5, default=logging.INFO) # JID and password options. optp.add_option("-j", "--jid", dest="jid", help="JID to use") optp.add_option("-p", "--password", dest="password", help="password to use") opts, args = optp.parse_args() # Setup logging. logging.basicConfig(level=opts.loglevel, format='%(levelname)-8s %(message)s') opts.jid = "censord@chat.facebook.com" opts.password = censored # Setup the EchoBot and register plugins. Note that while plugins may # have interdependencies, the order in which you register them does # not matter. xmpp = EchoBot(opts.jid, opts.password) xmpp.register_plugin('xep_0030') # Service Discovery xmpp.register_plugin('xep_0004') # Data Forms xmpp.register_plugin('xep_0060') # PubSub xmpp.register_plugin('xep_0199') # XMPP Ping # If you are working with an OpenFire server, you may need # to adjust the SSL version used: # xmpp.ssl_version = ssl.PROTOCOL_SSLv3 # If you want to verify the SSL certificates offered by a server: # xmpp.ca_certs = "path/to/ca/cert" # Connect to the XMPP server and start processing XMPP stanzas. if xmpp.connect(): # If you do not have the dnspython library installed, you will need # to manually specify the name of the server if it does not match # the one in the JID. For example, to use Google Talk you would # need to use: # # if xmpp.connect(('talk.google.com', 5222)): # ... xmpp.process(block=True) print("Done") else: print("Unable to connect.")upstart script
This simply starts fbReplyBot.py when the operating system boots, or to be more precise, when the network card starts.
# /etc/init/facebookBot.conf description "Tells people to talk to me via other means than Facebook" # start when the network card starts start on (local-filesystems and net-device-up IFACE=eth0) stop on shutdown # Automatically Respawn: respawn respawn limit 1 60 script # Not sure why $HOME is needed, but we found that it is: export HOME="/var/www/webxmpp" exec $HOME/fbReplyBot.py &gt;&gt; /dev/null end scriptOther Things Learned
I learned a lot about Inkscape ("an Open Source vector graphics editor") in creating the flow diagram in this blog post. I've always struggled finding good diagramming tools for Linux. I have researched the topic plenty and have yet to find something that has met my needs. If I had to, I could resort to cloud based diagramming tools, but, that feels like cheating to me, an admission that the Linux ecosystem lacks in some way. This was basically my first time using Inkscape. It feels like a fairly promising diagramming tool. The big revelation I had with Inkscape allowing me to recognize it as a powerful diagraming tool, was discovering the cloning functionality. In Inkscape, you can clone something which you have drawn, making several duplicates from a master. Then you can modify the master, such as the colour and have the changes be reflected in the cloned children. This is a huge plus when you have created a bunch of objects then want to change the colour of them. That said, there was a quirky aspect of its functionality that almost caused me to lose confidence. When resizing children the border thickness is scaled along with the resizing, that is, when you made the cloned child smaller, the border got skinnier, and when you made the child larger, the border got larger, but I wanted the border width to stay the same. There is an option in Inkscape that promises just this. It says that it maintains the boarder thickness when the object is scaled and I figured it would work for everything. However, it turns out that it does not work for cloned objects. The general way I overcame this was by drawing the boarders separately, but still making use of duplicating capabilities so that it wasn't a completely manual process. Additionally, there was a strange aspect that an arrow head on a line would not naturally match the colour of the line. To make it match according to this you have to go to: Extensions > Modify Path > Color Markers to Match Stroke. I used this, and it works, but it did cause me some confusion as to why this doesn't happen by default.
Also, just as I was finishing up this post, wordpress did this to my sourcecode, adding in br's all over the place, new paragraphs, replacing characters with HTML encoding etc. This is the type of thing that just makes you want to give up or leave it looking bad. But, I went back and I think I corrected everything. If you see some random br's or 's anywhere this is why. It also drives home the point as to why many developers refrain from using visual designers, because of mess-ups like these.
Resources and Thanks
I wouldn't have been able to do all this without help from other people on the Internet. Below is a list of many of the resources that helped me in the creation of this application.
- net tuts+ - How to Create A Simple Web-based Chat Application - this taught me the concept of how to create a section on a webpage, a box, that could have scrolling content in it that updates. It gave me the idea of including HTML in the chat log, and then simply displaying the content of the chat log into a scrollable area/div. If it weren't for this I would have attempted to creat additional elements on the page when each new message is created at either end of the conversation. Admittedly describing what I learned here was a bit difficult, and I'm not sure if I did a good job at it, but this was a useful resource!
- SleekXMPP - Without this project my project may simply not exist. This allowed me to connect to my Openfire/XMPP server from Python. This really shows one of the strengths of object oriented programming. I was able to simply drop in, or include the functionality of SleekXMPP and suddenly I was able to connect to my Openfire/XMPP server, something I'm not sure I would have ever been able to do otherwise since it is my guess that the programming involved in doing so would be over my head.
- Openfire - This is the XMPP chat server I am using. It plays a critical role in this application.
- Inkscape - cloning and tiling - wiki tutorial - This is probably the primary reason why my flow diagram above looks good. It introduced me to cloning in Inkscape.
- Stackoverflow - info on Curl - This showed me how to make a web request and receive the response of the request using Curl.
- Stackoverflow - info on browser detection - This showed me some of the techniques I used for browser detection.
- DigitalOcean - SSL Apache Ubuntu 12.04 - This helped me setup SLL on my Apache server.
- This blog for refreshing me on how to use Python and CGI for web programming.
- And many of the tools that I used: Ubuntu, Apache, PHP, Python, Eclipse IDE, Pidgin chat
- and many others I have neglected.
Demonstration
Below are two videos. The first is a demonstration of the chat application. The second is a demonstration of some of my new Inkscape skills. There is some strange glitches in the second demo, I suspect it is just because I am having some mouse issues in the virtual machine I was using. -
Automatically change file group permissions to that of parent
I was working with /var/www for some web stuff. The group and user owner of /var/www is www-data (Apache). I wanted to be able to work in in /var/www with my own user. So, I added myself to the www-data group with the command "usermod -a -G www-data myUser" and then I ran "chmod g+s /var/www -R" which now means that every file created under /var/www becomes part of the /var/www group, even files created by me.
-
Windows batch rename / extension to lowercase
Here is my first Windows post ever. I was looking to rename several .JPG files to .jpg that were all located in a folder. All I had to do was "cd" to the appropriate folder and run "ren *.JPG *.jpg" then I was done!
-
kernel 3.5.0-18 blank screen
I updated to kernel 3.5.0-18 with my Ubuntu 12.10 install and after restarting it would not boot, I would get a blank screen when I feel as though I should have been getting the login manager. It seems this was an issue with the Nvidia drivers. The following (followed by a restart) is what seemed to get things working for me.
apt-get purge nvidia-current apt-get purge nvidia-settings apt-get install linux-headers-3.5.0-18 apt-get install linux-headers-3.5.0-18-generic apt-get install nvidia-current nvidia settingsI may have not had to install two sets of headers, but, it wasn't worth my time determining this.
-
SSHFS + Nautilus + Delete Folders with Files
I am using autofs in conjunction with SSHFS to mount some remote folders. When attempting to remove/delete non-empty folders from the mounted folder using Nautilus I ran into issues. I would get "Error removing file: Operation not permitted" or "Error while deleting." The workaround I used to overcome this issue was to create a folder named .Trash in the mounted folder with 1777 permissions. One aspect to note here is that if you mounted a folder located on the remote file system at /mnt/content/a/ for example, and you are trying to remove a folder named "coffee" located at /mnt/content/a/b/c/d/e/coffee/ on the remote server .Trash needs to exist in /mnt/content/a/ not /mnt/content/a/b/c/d/e/. But! Then the files will be left in .Trash, thus, you will need to account for that, perhaps through a cronjob.
-
Cuda5 on Ubuntu 12.10
To install Cuda5 on Ubuntu 12.10 I needed to do a few extra things. Below are the steps I took, there are improvements I suspect what could be made, but I will present instead what worked for me. If I were to do it again I suspect I would do it slightly more efficiently. I did this for the purposes of using Boinc, and used Boinc to test that it works. I was not able to install the samples but this seems to not be an issue.
- I downloaded the Ubuntu 11.10 64bit installer from here http://developer.nvidia.com/cuda/cuda-downloads
- I moved the file to /root/ because my home folder is encrypted
- I restarted into recovery mode
- dropped to root shell
- I ran # mount -n -o remount,rw /
- moved to /root/ directory
- gave the downloaded file execute permissions
- I ran the file
- Only the driver installation succeeded, the other two, the SDK and the samples failed
- I rebooted my computer normally
- I installed gcc-4.6 (apt-get install gcc-4.6)
- changed directory to /usr/bin
- removed gcc (it's a symbolic link to gcc-4.7)
- created a symbolic link to gcc-4.6 (ln -s gcc-4.6 gcc)
- changed directory to /root/ and re-ran the downloaded file, only selecting yes to the SDK and samples
- The SDK succeeded, but the samples failed
- I was not able to get the samples to work, in my random attempts to fix this I tried to install: libglut-dev, libglew-dev and freeglut3-dev. I don't think these did anything, I can't even remember if all of them exist, I am just including this for completeness.
- I restarted my system
- I ran
- $ export LDLIBRARYPATH=/usr/local/cuda-5.0/lib:$LDLIBRARYPATH
- $ export LDLIBRARYPATH=/usr/local/cuda-5.0/lib:$LDLIBRARYPATH
- Then for my own tastes, I restarted boinc (# /etc/init.d/boinc-client restart)
- And Boinc was able to take advantage of the Cuda abilities, hence, it worked despite not getting the samples installed.
- I will still need to add the export commands to ~/.bashprofile or something similar. I say something similar because /etc/init.d/boinc-client seems to run before ~/.bashprofile and thus doing this requires you to restart boinc after startup. This however, is something for my to do list.
- Lastly, I recreated the symbolic link in /usr/bin to gcc-4.7
-
UnicodeEncodeError
I was getting this error
UnicodeEncodeError: 'ascii' codec can't encode character u'\xae' in position 44817: ordinal not in range(128)when trying to dump some output from Python. Since I was only temporarily trying to dump some output I found that surrounding my offending content with repr(), that is, "print (repr(offendingContent))" while printing solved the problem good enough for the context.
-
Code Snippets for FB Delete
I used the code below to delete items from my activity log on Facebook which were mixed in with items that were not able to be deleted. It is an improvement on http://www.torypages.com/blog/?p=1165 because it doesn't depend on all items being deletable. The code contained in the link I just provided only deletes whatever item is at the top of the log, thus rendering it useless if the item at the top of the log is not deletable. The code below instead traverses down the Facebook activity log instead of taking whatever is at the top. You could even adjust the "myCounter" variable and skip over the first n activity log entries allowing you to only delete older items.
The catch blocks are probably entirely rubbish, I have no idea what they do if anything, but I don't have time to test them, or perfect them, all I know is that the following code helped me greatly. Hopefully someone else will take the ideas and run with them.
var to1, to2, to3, to4, to5; var myCounter = -1; function myStart(){ myCounter = myCounter + 1; task1(); } function task1(){ try { //alert(myCounter); myName = 'toryUnique' + myCounter; //alert(myName); $jq('a[ajaxify*="show_story_options"]:eq(' + myCounter + ')').attr('id', myName); document.getElementById(myName).click(); } catch (err) { window.clearTimeout(to1); //no idea if these are needed window.clearTimeout(to2); window.clearTimeout(to3); window.clearTimeout(to4); // something dint' work right, just window.clearTimeout(to5); // start over. If something didn't myStart(); // work right it is probably because return; // a delay was too short } to1 = window.setTimeout(function(){ task2(); }, 1000); //800 millisecond delay } function task2(){ try { // alert('test'); myOtherName = 'toryOtherUnique' + myCounter; $jq("span:contains(Delete):last").parent().attr('id', myOtherName); document.getElementById(myOtherName).click(); myOtherOtherName = 'toryOtherOtherUnique' + myCounter; $jq("a:contains(Delete)").attr('id', myOtherOtherName); } catch (err) { window.clearTimeout(to1); window.clearTimeout(to2); window.clearTimeout(to3); window.clearTimeout(to4); window.clearTimeout(to5); myStart(); return; } to2 = window.setTimeout(function(){ task3(); }, 1000); } function task3(){ try { myOtherOtherName = 'toryOtherOtherUnique' + myCounter; document.getElementById(myOtherOtherName).click(); } catch (err) { window.clearTimeout(to1); window.clearTimeout(to2); window.clearTimeout(to3); window.clearTimeout(to4); window.clearTimeout(to5); myStart(); return; } to3 = window.setTimeout(function(){ task4(); }, 400); } function task4(){ try { superUniqueTory = "superUniqueTory" + myCounter $jq('input[value="Delete"]').attr('id', superUniqueTory); document.getElementById(superUniqueTory).click(); } catch (err) { window.clearTimeout(to1); window.clearTimeout(to2); window.clearTimeout(to3); window.clearTimeout(to4); window.clearTimeout(to5); myStart(); return; } to4 = window.setTimeout(function(){ myStart(); }, 2000); } myStart();The following code works in much the same way as above, but this code will hide the items from your timeline instead of deleting them. Ideally the code above, and the code below would be combined into one.
var to1, to2; var myCounter = -1; function myStart(){ myCounter = myCounter + 1; task1(); } function task1(){ try { //alert(myCounter); myName = 'toryUnique' + myCounter; //alert(myName); $jq('a[ajaxify*="show_story_options"]:eq(' + myCounter + ')').attr('id', myName); document.getElementById(myName).click(); } catch (err) { window.clearTimeout(to1); //no idea if these are needed window.clearTimeout(to2); //window.clearTimeout(to3); //window.clearTimeout(to4); // something dint' work right, just //window.clearTimeout(to5); // start over. If something didn't //myStart(); // work right it is probably because return; // a delay was too short } to1 = window.setTimeout(function(){ task2(); }, 1000); //800 millisecond delay } function task2(){ try { // alert('test'); myOtherName = 'toryOtherUnique' + myCounter; $jq("span:contains(Hidden from timeline):last").parent().attr('id', myOtherName); document.getElementById(myOtherName).click(); } catch (err) { window.clearTimeout(to1); window.clearTimeout(to2); //window.clearTimeout(to3); //window.clearTimeout(to4); //window.clearTimeout(to5); //myStart(); return; } to2 = window.setTimeout(function(){ myStart(); }, 1000); } myStart();As I noted here http://www.torypages.com/blog/?p=1165 Javascript confuses me, I'm mearely trying to scratch my own itch here, I have no interest or time to perfect this, just needed to get it done even if in a very sloppy way. I'm simply posting to spark other people's imaginations. It took my a long time to even figure out that Javascript in the browser's Javascript console would be a way of doing this. But my code here makes for proof of concept. Ideally this would be implemented in a Greasemonkey script I suppose.